Welcome to Journal of Automotive Safety and Energy,
Journal of Automotive Safety and Energy ›› 2024, Vol. 15 ›› Issue (5): 702-710.DOI: 10.3969/j.issn.1674-8484.2024.05.008
• Intelligent Driving and Intelligent Transportation • Previous Articles Next Articles
LIU Peng1( ), ZHAO Kegang1,*(), LIANG Zhihao1, YE Jie2
), ZHAO Kegang1,*(), LIANG Zhihao1, YE Jie2
Received:2024-05-15
Revised:2024-10-09
Online:2024-10-31
Published:2024-11-07
CLC Number:
LIU Peng, ZHAO Kegang, LIANG Zhihao, YE Jie. Vehicle longitudinal speed planning based on deep reinforcement learning CLPER-DDPG[J]. Journal of Automotive Safety and Energy, 2024, 15(5): 702-710.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.journalase.com/EN/10.3969/j.issn.1674-8484.2024.05.008
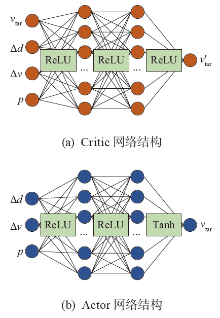
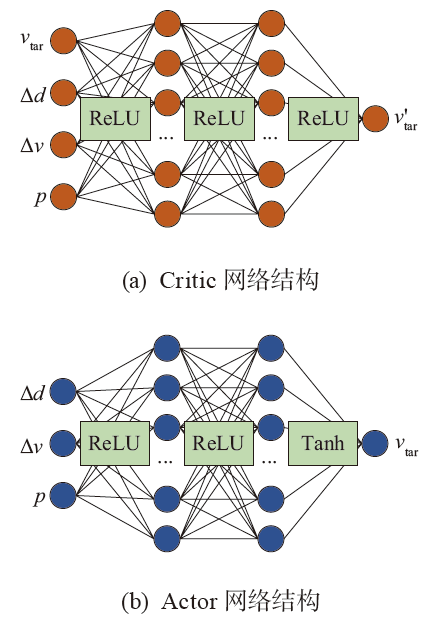
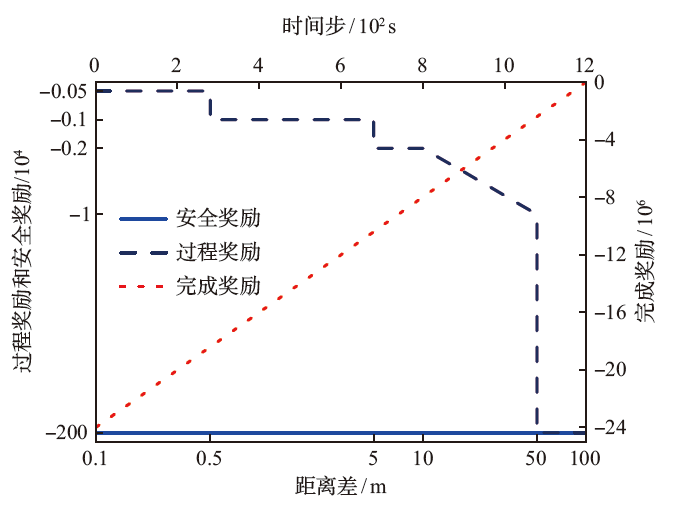
| 超参数 | 数值 |
|---|---|
| 最大回合数,K | 1 000 |
| 每回合时间步,T | 1 200 |
| 经验回放池最大容量,Dmax | 100 000 |
| 批量训练数量,batch | 64 |
| 网络学习率,lr | 0.001 |
| 折扣因子,γ | 0.995 |
| 软更新系数,η | 0.02 |
| PER超参数,[ε, α, β] | [0.01, 0.8, 0.4] |
| 权重系数,[ζ1, ζ2, ζ3, ζ4] | [8, 2, 1, 0.1] |
| 聚合因子,χ | 0.000 1 |
| 超参数 | 数值 |
|---|---|
| 最大回合数,K | 1 000 |
| 每回合时间步,T | 1 200 |
| 经验回放池最大容量,Dmax | 100 000 |
| 批量训练数量,batch | 64 |
| 网络学习率,lr | 0.001 |
| 折扣因子,γ | 0.995 |
| 软更新系数,η | 0.02 |
| PER超参数,[ε, α, β] | [0.01, 0.8, 0.4] |
| 权重系数,[ζ1, ζ2, ζ3, ζ4] | [8, 2, 1, 0.1] |
| 聚合因子,χ | 0.000 1 |
| 随机初始化: |
|---|
| Critic网络Q(s, a|θ Q)和Actor网络μ(s|θ μ); |
| Target-Critic网络Q(s, a|θ Q')和Target-Actor网络μ(s|θ μ'); |
| 经验回放池D。 |
| For (S, K) ? {(S1, K1), (S2, K2), (S3, K3), (S4, K4)} do: |
| For episode = 1, …, K do: |
| 初始化起始状态s1 |
| For t = 1, …, T do: |
| 根据策略和OU噪声输出动作at = μ(st|θ μ) + Nt |
| 获取奖励rt以及下一时刻的状态st + 1 |
| 将数据(st, at, rt, st + 1)以最大优先级存储到经验回放池D中 |
| For i = 1, …, D do: |
| 基于概率Pi采样样本 |
| 计算重要性采样权重、TD绝对误差|δi|和样本优先级pi |
| End |
| 更新Critic网络和Actor网络 |
| 更新Target-Critic和Target-Actor网络 |
| End |
| End |
| End |
| 随机初始化: |
|---|
| Critic网络Q(s, a|θ Q)和Actor网络μ(s|θ μ); |
| Target-Critic网络Q(s, a|θ Q')和Target-Actor网络μ(s|θ μ'); |
| 经验回放池D。 |
| For (S, K) ? {(S1, K1), (S2, K2), (S3, K3), (S4, K4)} do: |
| For episode = 1, …, K do: |
| 初始化起始状态s1 |
| For t = 1, …, T do: |
| 根据策略和OU噪声输出动作at = μ(st|θ μ) + Nt |
| 获取奖励rt以及下一时刻的状态st + 1 |
| 将数据(st, at, rt, st + 1)以最大优先级存储到经验回放池D中 |
| For i = 1, …, D do: |
| 基于概率Pi采样样本 |
| 计算重要性采样权重、TD绝对误差|δi|和样本优先级pi |
| End |
| 更新Critic网络和Actor网络 |
| 更新Target-Critic和Target-Actor网络 |
| End |
| End |
| End |
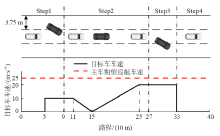
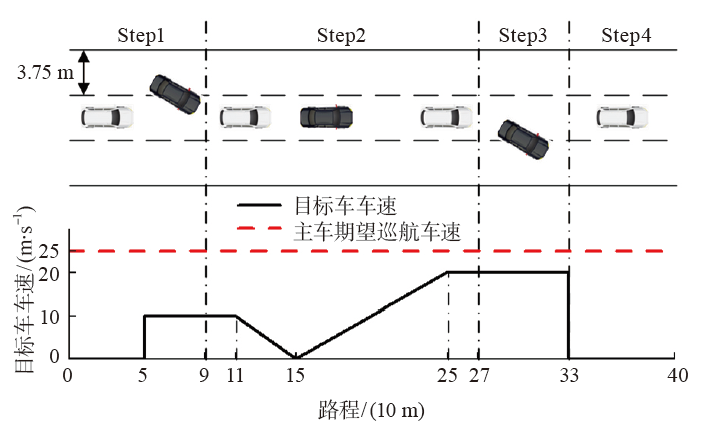
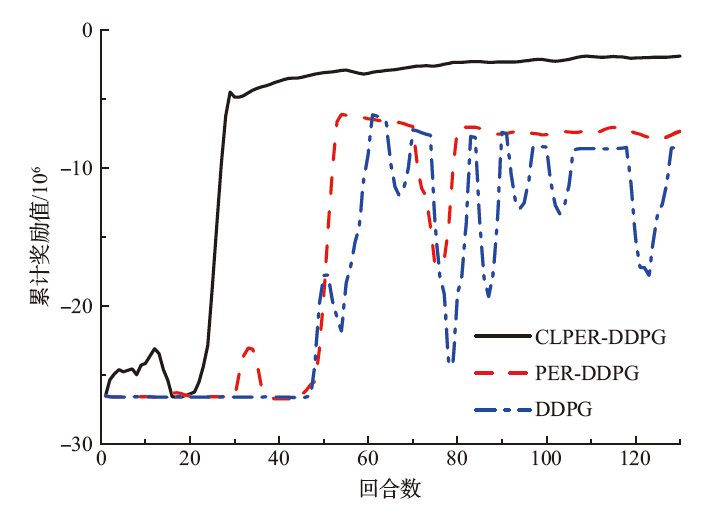
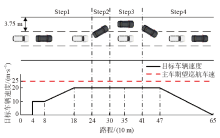
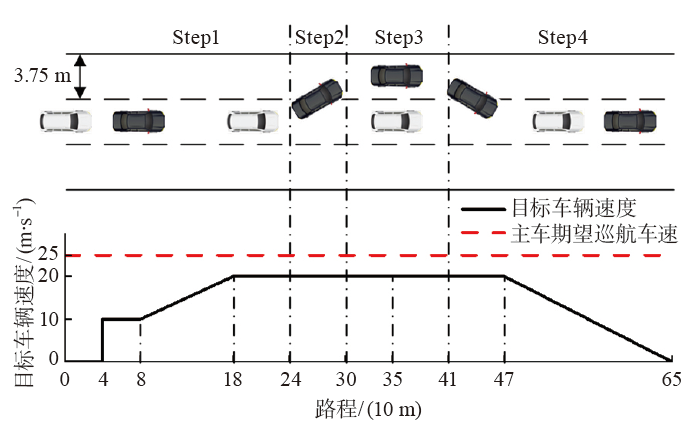
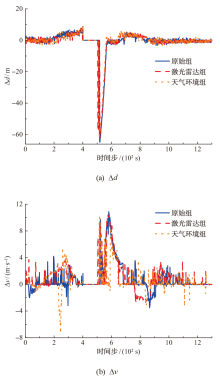
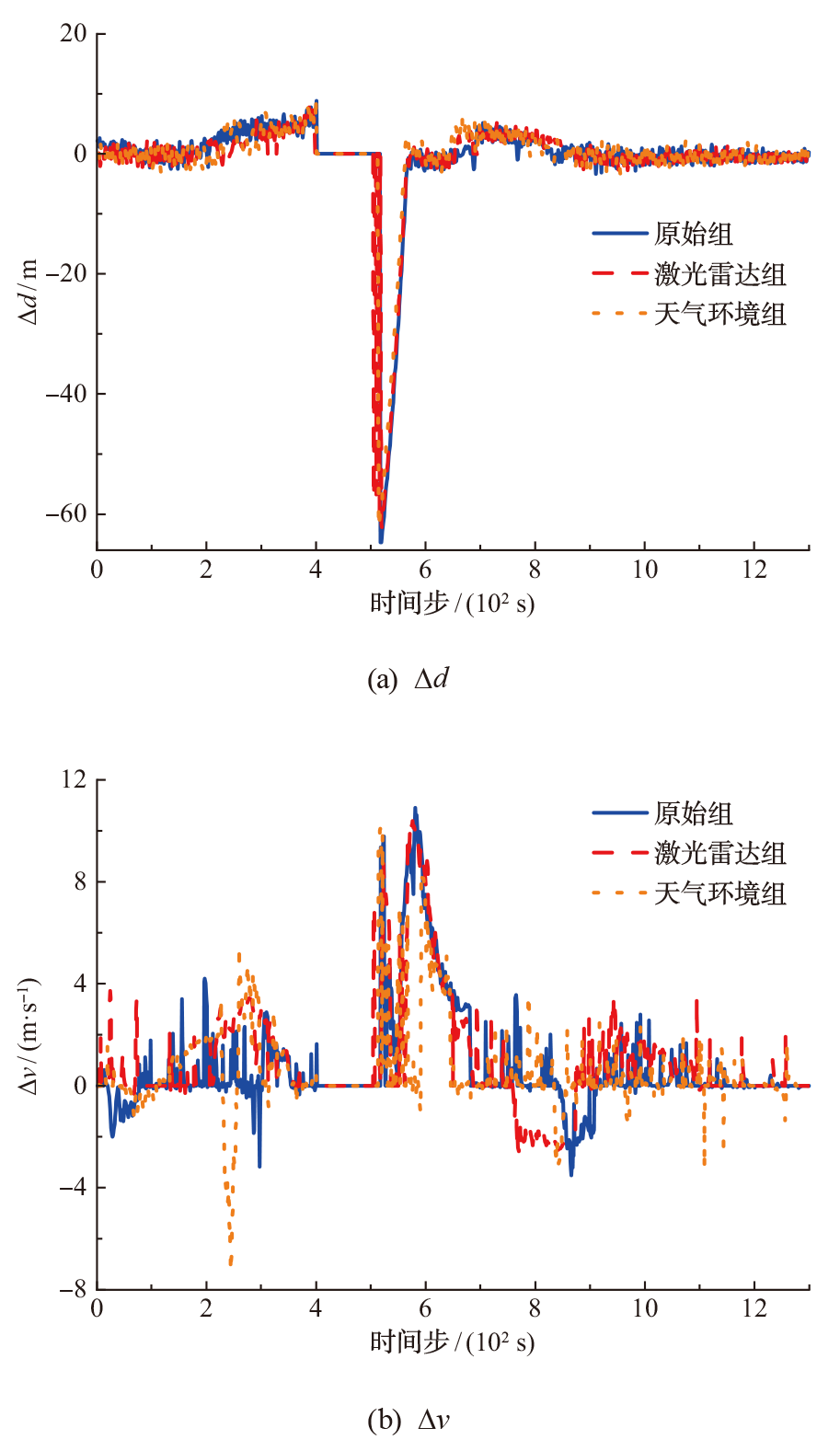


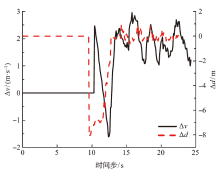
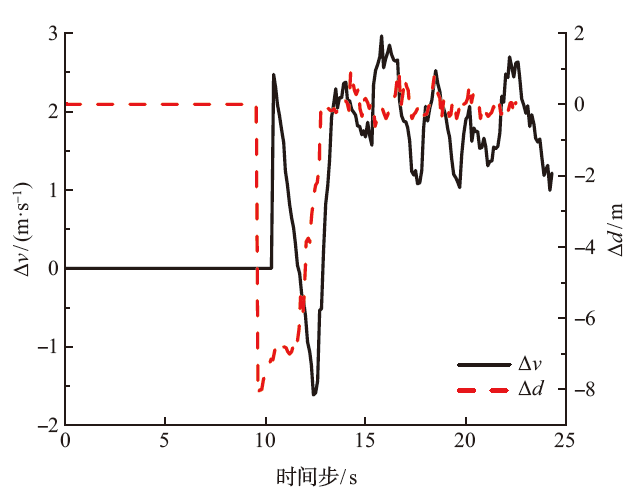
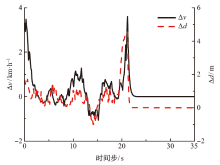
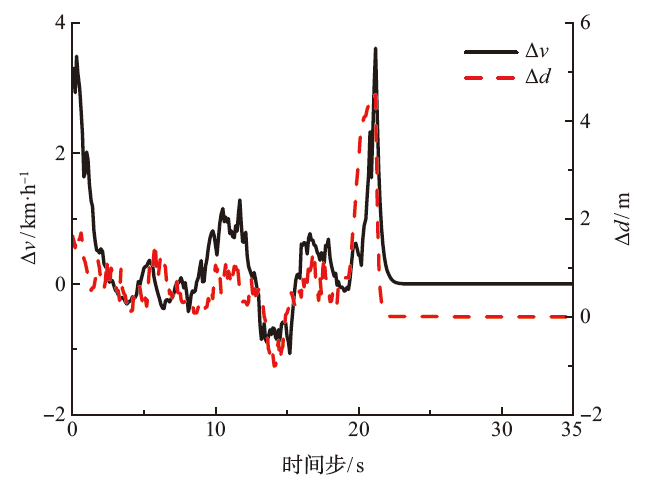
| [1] |
林泓熠, 刘洋, 李深, 等. 车路协同系统关键技术研究进展[J]. 华南理工大学学报(自然科学版), 2023, 51(10): 46-67.
doi: 10.12141/j.issn.1000-565X.230200 |
| LIN Hongyi, LIU Yang, LI Shen, et al. Research progress on key technologies in the cooperative vehicle infrastructure system[J]. J South Chin Univ Tech (Nat Sci Edit), 2023, 51(10): 46-67. (in Chinese) | |
| [2] | 芦勇, 何一超, 田贺, 等. 面向量产的自适应巡航控制系统纵向加速度规划方法研究[J]. 汽车工程, 2023, 45(10): 1803-1814. |
| LU Yong, LE Yichao, TIAN He, et al. Research on longitudinal acceleration planning method of adaptive cruise control system for mass production[J]. Autom Engineering, 2023, 45(10): 1803-1814. (in Chinese) | |
| [3] | 李旭, 谢宁, 王建春, 等. 面向切入场景的变权重自适应巡航控制策略[J]. 重庆理工大学学报(自然科学), 2023, 37(4): 10-18. |
| LI Xu, XIE Ning, WANG Jianchun. Variable weight adaptive cruise control strategy for cut-in scenes[J]. J Chongqing Univ Tech (Nat Sci), 2023, 37(4): 10-18. (in Chinese) | |
| [4] | 张德兆, 王建强, 刘佳熙, 等. 加速度连续型自适应巡航控制模式切换策略[J]. 清华大学学报(自然科学版), 2010, 50(8): 1277-1281. |
| ZHANG Dezhao, WANG Jianqiang, LIU Jiaxi, et al. Switching strategy for adaptive cruise control modes for continuous acceleration[J]. J Tsinghua Univ (Sci Tech), 2010, 50(8): 1277-1281. (in Chinese) | |
| [5] | ZHOU Yang, Ahn S, Chitturi M, et al. Rolling horizon stochastic optimal control strategy for ACC and CACC under uncertainty[J]. Transport Res Part C: Emerg Tech, 2017, 83: 61 Chinese -76. |
| [6] | CHU Hongqing, GUO Lulu, YAN Yongjun, et al. Self-learning optimal cruise control based on individual car-following style[J]. IEEE Trans Intel Transport Syst, 2020, 22(10): 6622-6633. |
| [7] |
韩天园, 沈永俊, 鲍琼, 等. 基于类人决策与横纵向协同的车辆弯道自适应巡航控制策略[J]. 中国公路学报, 2023, 36(10): 211-223.
doi: 10.19721/j.cnki.1001-7372.2023.10.017 |
| HAN Tianyuan, SHEN Yongjun, BAO Qiong, et al. Adaptive cruise control strategy for vehicle at curves based on human-like decision-making and lateral-longitudinal coordination[J]. China J Highway Transport, 2023, 36(10): 211-223. (in Chinese) | |
| [8] | 李涵, 余贵珍, 周彬, 等. 面向非结构化道路场景的车辆全局速度规划[J]. 汽车安全与节能学报, 2023, 14(3): 319-328. |
| LI Han, YU Guizhen, ZHOU Bin, et al. Vehicle global speed planning for unstructured roads scenario[J]. J Autom Safe Energ, 2023, 14(3): 319-328. (in Chinese) | |
| [9] | 何逸煦, 林泓熠, 刘洋, 等. 强化学习在自动驾驶技术中的应用与挑战[J]. 同济大学学报(自然科学版), 2024, 52(4): 520-531. |
| HE Yixu, LIN Hongyi, LIU Yang, et al. Applications and challenges of reinforcement learning in autonomous driving technology[J]. J Tongji Univ (Nat Sci), 2024, 52(4): 520-531. (in Chinese) | |
| [10] | 张新锋, 吴琳. 基于集成深度强化学习的自动驾驶车辆行为决策模型[J]. 汽车安全与节能学报, 2023, 14(4): 472-479. |
| ZHANG Xinfeng, WU Lin. Behavior decision-making model for autonomous vehicles based on an ensemble deep reinforcement learning[J]. J Autom Safe Energ, 2023, 14(4): 472-479. (in Chinese) | |
| [11] | LI Guoqiang, Görges D. Ecological adaptive cruise control for vehicles with step-gear transmission based on reinforcement learning[J]. IEEE Trans Intel Transport Syst, 2019, 21(11): 4895-4905. (in Chinese) |
| [12] |
朱冰, 蒋渊德, 赵健, 等. 基于深度强化学习的车辆跟驰控制[J]. 中国公路学报, 2019, 32(6): 53-60.
doi: 10.19721/j.cnki.1001-7372.2019.06.005 |
| ZHU Bing, JIANG Yuande, ZHAO Jian, et al. A car-following control algorithm based on deep reinforcement learning[J]. Chin J Highway Transport, 2019, 32(6): 53-60. (in Chinese) | |
| [13] | Nevmyvaka Y, FENG Yi, Kearns M. Reinforcement learning for optimized trade execution[C]// Proceed 23rd Int’l Conf Mach Learn. Pittsburgh, Pennsylvania, USA. 2006: 673-680. |
| [14] | CHENG Nuo, WANG Peng, ZHANG Guangyuan, et al. Prioritized experience replay in path planning via multi-dimensional transition priority fusion[J]. Front Neurorobot, 2023, 15(17): 171281166-1281166. |
| [15] | Golovin N, Rahm E. Reinforcement learning architecture for web recommendations[C]// Int’l Conf Info Tech: Coding Comput, 2004. Proceed. ITCC 2004. IEEE, 2004, 1: 398-402. |
| [16] | XUE Honghu, Benedikt H, Mohamed B, et al. Using deep reinforcement learning with automatic curriculum learning for mapless navigation in intralogistics[J]. Appl Sci, 2022, 12(6): 3153-3153. (in Chinese) |
| [17] |
万里鹏, 兰旭光, 张翰博, 等. 深度强化学习理论及其应用综述[J]. 模式识别与人工智能, 2019, 32(1): 67-81.
doi: 10.16451/j.cnki.issn1003-6059.201901009 |
| PENG Wanli, LAN Xuguang, ZHANG Zhang. A review of deep reinforcement learning theory and application[J]. Patt Recog Artif Intel, 2019, 32(1): 67-81. (in Chinese) | |
| [18] | Volodymyr M, Koray K, David S, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-33. |
| [19] | Lillicrap P T, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[C]// Int’l Conf Learn Represent. Google Deepmind, London, UK, 2016. |
| [1] | CAO Liling, LIU Junli, JIN Shengye, CAO Shouqi, ZHOU Guofeng. Design of a remote multidimensional information real time interaction system for autonomous driving [J]. Journal of Automotive Safety and Energy, 2024, 15(6): 934-942. |
| [2] | LIU Yang, ZHAN Jiahao, LI Shen, LI Xiaopeng, CHEN Jun. Future of autonomous driving: Single autonomous driving and intelligent vehicle-infrastructure collaboration systems [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 611-633. |
| [3] | QU Guangyue, YANG Lan, YUAN Meng, FANG Shan, LIU Songyan. A multimodal trajectory prediction method of pedestrians at signalized intersections for autonomous vehicles [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 689-701. |
| [4] | GAO Kai, LIU Jian, LIU Linhong, LIU Xinyu, ZHANG Jinlai, DU Ronghua. Explainable lane change intention prediction based on LSTM-multi-head mixed attention [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 763-773. |
| [5] | ZHENG Xunjia, JIANG Junhao, LI Huilan, CHEN Xing, LIU Hui, WANG Jianqiang, GAO Jianjie. Research on transient driving risk vector modeling method under strong constraints of traffic regulations [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 774-782. |
| [6] | XIE Zhen, ZHOU Guofeng, WU Mingyu, CAO Shouqi. Research on dynamic modeling of port autonomous driving truck [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 783-794. |
| [7] | ZHANG Yongsheng, LI Yizhou, WANG Liang, XU Zhigang. Development status and challenges of vehicle terminals in intelligent and connected environments [J]. Journal of Automotive Safety and Energy, 2024, 15(3): 295-308. |
| [8] | LI Caihong, HE Chenyang, GAO Feng, CHEN Jiaxin. A dynamic clustering algorithm based on the point clouds distribution characteristics of obstacle [J]. Journal of Automotive Safety and Energy, 2024, 15(2): 261-267. |
| [9] | ZHANG Xinfeng, WU Lin, LI Zhiyuan, LIU Huan. Collaborative decision-making method of high-speed multi-vehicle multi-driving behavior confliction [J]. Journal of Automotive Safety and Energy, 2023, 14(5): 609-617. |
| [10] | ZHANG Xinfeng, WU Lin. Behavior decision-making model for autonomous vehicles based on an ensemble deep reinforcement learning [J]. Journal of Automotive Safety and Energy, 2023, 14(4): 472-479. |
| [11] | HUANG Pengcheng, PEI Xiaofei, ZHOU Honglong, CHEN Ci. Trajectory planning algorithm of autonomous vehicle based on multi-index coupling [J]. Journal of Automotive Safety and Energy, 2023, 14(4): 480-487. |
| [12] | ZHANG Yaqin, LI Zhenyu, SHANG Guobin, ZHOU Guyue, GAO Guorong, YUAN Jirui. A unified framework for vehicle-infrastructure-cloud autonomous driving [J]. Journal of Automotive Safety and Energy, 2023, 14(3): 249-273. |
| [13] | LI Han, YU Guizhen, ZHOU Bin, ZHANG Yudi, OUYANG Dongzhe, TIAN Jiangtao. Vehicle global speed planning for unstructured roads scenario [J]. Journal of Automotive Safety and Energy, 2023, 14(3): 319-328. |
| [14] | LI Pingfei, JIN Siyu, HU Wenhao, GAO Li, CHE Yaoyu, TAN Zhengping, DONG Xiaofei. Complexity evaluation of vehicle-vehicle accident scenarios for autonomous driving simulation tests [J]. Journal of Automotive Safety and Energy, 2022, 13(4): 697-704. |
| [15] | ZHU Bo, ZHANG Jiwei, TAN Dongkui, HU Xudong. End-to-end autonomous driving method based on multi-source sensor and navigation map [J]. Journal of Automotive Safety and Energy, 2022, 13(4): 738-749. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||