Welcome to Journal of Automotive Safety and Energy,
Journal of Automotive Safety and Energy ›› 2025, Vol. 16 ›› Issue (5): 793-801.DOI: 10.3969/j.issn.1674-8484.2025.05.014
• Intelligent Driving and Intelligent Transportation • Previous Articles Next Articles
PAN Yuheng( ), REN Chen, LU Weijia(), LI Yang
), REN Chen, LU Weijia(), LI Yang
Received:2025-07-11
Revised:2025-08-24
Online:2025-10-31
Published:2025-11-10
CLC Number:
PAN Yuheng, REN Chen, LU Weijia, LI Yang. DV-PointPillars 3D object detection model based on dual pooling attention mechanism and vertical feature fusion[J]. Journal of Automotive Safety and Energy, 2025, 16(5): 793-801.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.journalase.com/EN/10.3969/j.issn.1674-8484.2025.05.014
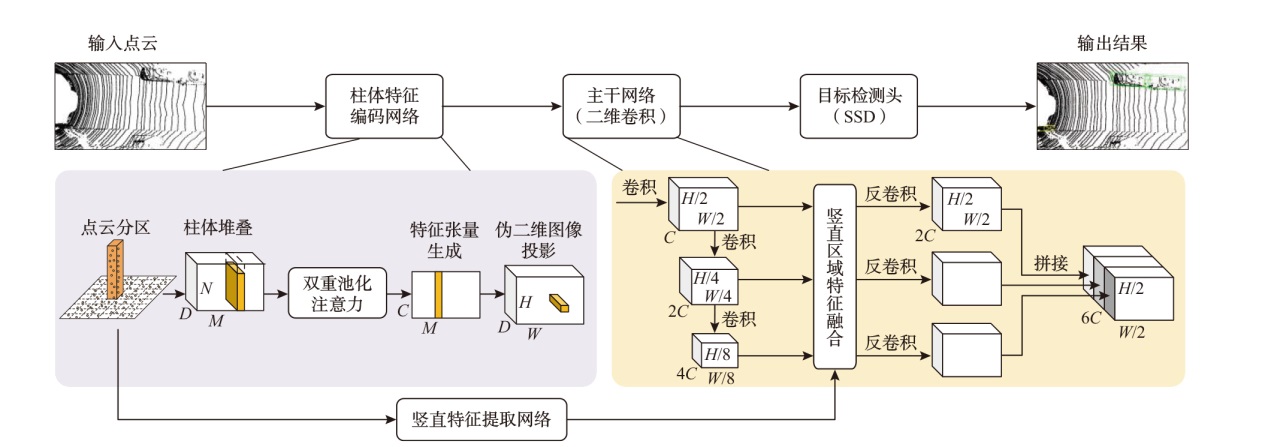
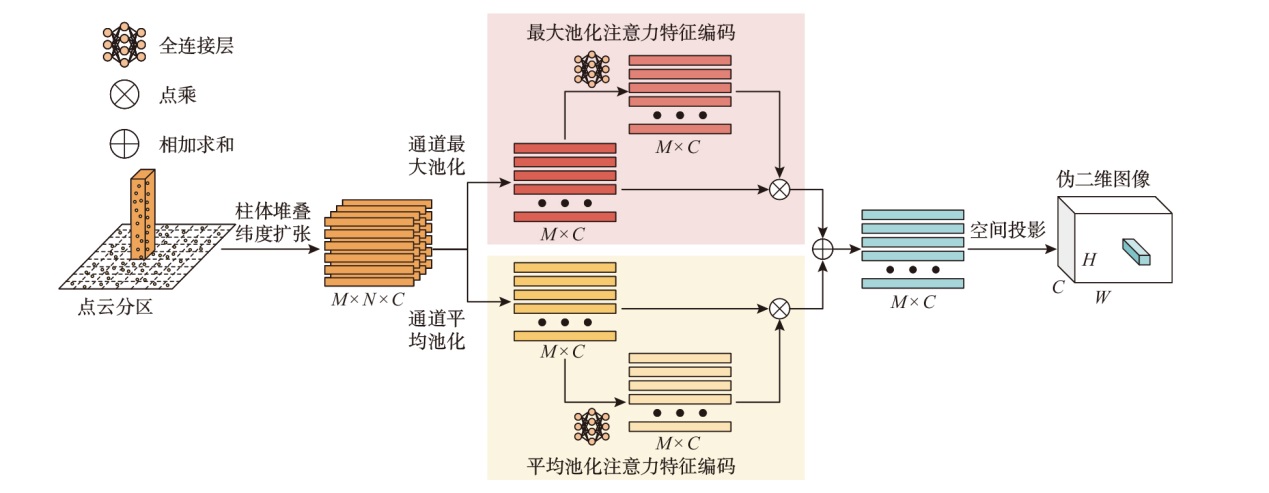
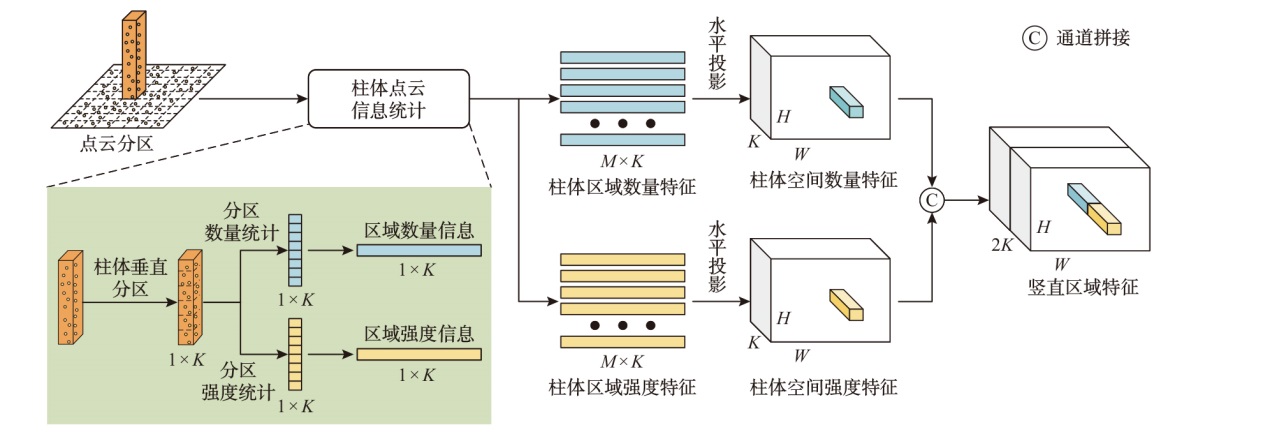
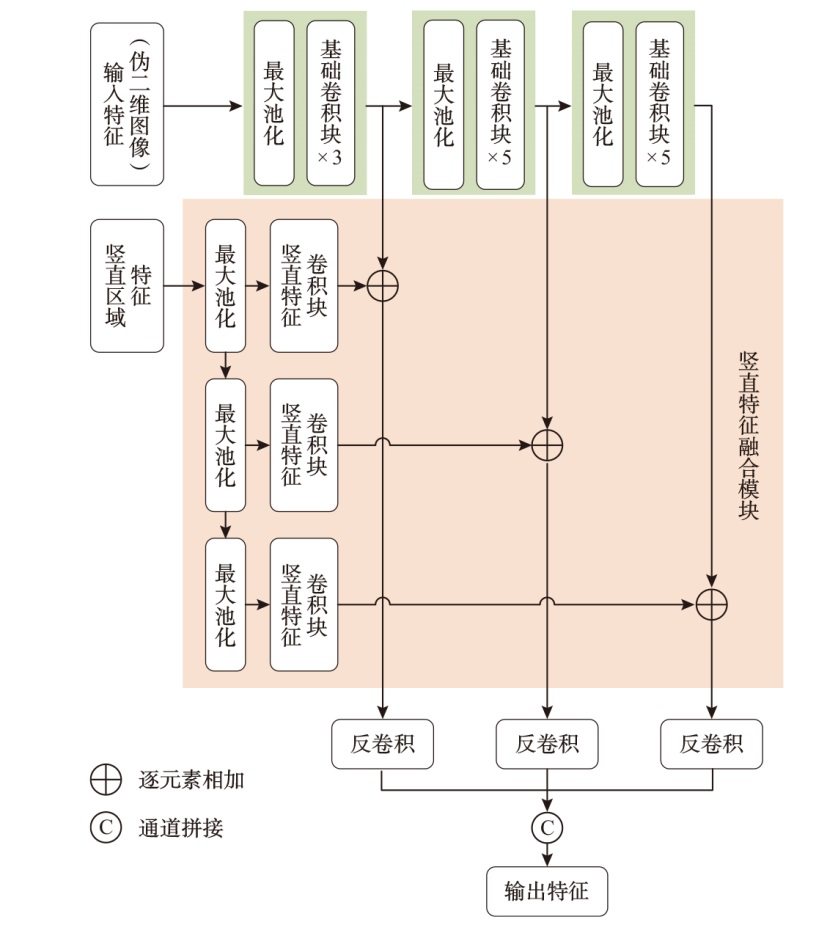
| 模型名称 | 汽车AP / % | 行人AP / % | 骑行者AP / % | 检测帧数/ fps | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| PointPillars | 83.80 | 72.56 | 69.49 | 48.19 | 42.53 | 38.66 | 71.96 | 59.64 | 55.37 | 37.32 | ||
| PointRCNN | 85.59 | 76.39 | 72.45 | 54.50 | 47.92 | 40.73 | 77.08 | 57.06 | 53.04 | 19.71 | ||
| SECOND | 86.93 | 76.88 | 72.75 | 49.59 | 44.58 | 40.28 | 72.40 | 60.17 | 56.46 | 27.87 | ||
| PillarNet | 84.95 | 75.37 | 72.26 | 46.18 | 40.87 | 36.06 | 76.19 | 56.75 | 53.08 | 25.95 | ||
| GCR-PointPillars | 85.26 | 75.08 | 72.29 | 49.42 | 43.00 | 38.72 | 76.93 | 59.12 | 54.73 | 18.64 | ||
| DCG-PointPillars | 87.06 | 75.86 | 72.71 | 50.41 | 43.62 | 39.34 | 75.30 | 57.76 | 53.77 | 23.81 | ||
| 本文DV-PointPillars | 87.41 | 77.31 | 73.17 | 54.71 | 47.68 | 42.51 | 81.79 | 62.16 | 58.32 | 28.78 | ||
| 模型名称 | 汽车AP / % | 行人AP / % | 骑行者AP / % | 检测帧数/ fps | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| PointPillars | 83.80 | 72.56 | 69.49 | 48.19 | 42.53 | 38.66 | 71.96 | 59.64 | 55.37 | 37.32 | ||
| PointRCNN | 85.59 | 76.39 | 72.45 | 54.50 | 47.92 | 40.73 | 77.08 | 57.06 | 53.04 | 19.71 | ||
| SECOND | 86.93 | 76.88 | 72.75 | 49.59 | 44.58 | 40.28 | 72.40 | 60.17 | 56.46 | 27.87 | ||
| PillarNet | 84.95 | 75.37 | 72.26 | 46.18 | 40.87 | 36.06 | 76.19 | 56.75 | 53.08 | 25.95 | ||
| GCR-PointPillars | 85.26 | 75.08 | 72.29 | 49.42 | 43.00 | 38.72 | 76.93 | 59.12 | 54.73 | 18.64 | ||
| DCG-PointPillars | 87.06 | 75.86 | 72.71 | 50.41 | 43.62 | 39.34 | 75.30 | 57.76 | 53.77 | 23.81 | ||
| 本文DV-PointPillars | 87.41 | 77.31 | 73.17 | 54.71 | 47.68 | 42.51 | 81.79 | 62.16 | 58.32 | 28.78 | ||
| 模块选择 | 实验数值AP / % | 检测帧数/ fps | |||||
|---|---|---|---|---|---|---|---|
| 最大池化 注意力模块 | 平均池化 注意力模块 | 竖直区域 特征融合 | 汽车 | 行人 | 骑行者 | ||
| 75.28 | 43.13 | 62.33 | 37.32 | ||||
| √ | 75.43 | 42.21 | 64.87 | 36.51 | |||
| √ | 76.26 | 43.89 | 63.22 | 36.42 | |||
| √ | √ | 76.62 | 44.53 | 65.07 | 36.09 | ||
| √ | 77.80 | 46.23 | 64.67 | 29.92 | |||
| √ | √ | √ | 79.30 | 48.30 | 67.42 | 28.78 | |
| 模块选择 | 实验数值AP / % | 检测帧数/ fps | |||||
|---|---|---|---|---|---|---|---|
| 最大池化 注意力模块 | 平均池化 注意力模块 | 竖直区域 特征融合 | 汽车 | 行人 | 骑行者 | ||
| 75.28 | 43.13 | 62.33 | 37.32 | ||||
| √ | 75.43 | 42.21 | 64.87 | 36.51 | |||
| √ | 76.26 | 43.89 | 63.22 | 36.42 | |||
| √ | √ | 76.62 | 44.53 | 65.07 | 36.09 | ||
| √ | 77.80 | 46.23 | 64.67 | 29.92 | |||
| √ | √ | √ | 79.30 | 48.30 | 67.42 | 28.78 | |


| [1] |
《中国公路学报》编辑部. 中国汽车工程学术研究综述·2023[J]. 中国公路学报, 2023, 36(11): 1-192.
doi: 10.19721/j.cnki.1001-7372.2023.11.001 |
| Editorial Department of China Journal of Highway and Transport. Review on China's automotive engineering research progress:2023[J]. China J Highw Transport, 2023, 36(11): 1-192. (in Chinese) | |
| [2] | QIAN Rui, LAI Xin, LI Xirong. 3D object detection for autonomous driving: A survey[J]. Patt Recogn, 2022, 130: No 108796. |
| [3] | ZHOU Yunsong, HE Yuan, ZHU Hongzi, et al. Monocular 3d object detection: an extrinsic parameter free approach[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Nashville, TN, USA, 2021: 7556-7566. |
| [4] | LI Peiliang, CHEN Xiaozhi, SHEN Shaojie. Stereo R-CNN based 3D object detection for autonomous driving[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Long Beach, CA, USA, 2019: 7636-7644. |
| [5] | CHEN Xiaozhi, MA Huimin, WAN Ji, et al. Multi-view 3D object detection network for autonomous driving[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Nashville, TN, USA, 2018: 6526-6534. |
| [6] | Qi C R, LIU W, WU Chenxia, et al. Frustum PointNets for 3D object detection from RGB-D data[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Salt Lake City, UT, USA, 2018: 918-927. |
| [7] | K Jason, Mozifian M, Lee J, et al. Joint 3D proposal generation and object detection from view aggregation[C]// Proc IEEE/RSJ Int’l Conf Intel Robot Syst (IROS). Madrid, Spain, 2018: 1-8. |
| [8] | Sindagi V A, ZHOU Yin, Tuzel O. MVX-Net: Multimodal VoxelNet for 3D object detection[C]// Proc Int’l Conf Robot Auto (ICRA). Montreal, Canada, 2019: 7276-7282. |
| [9] | Vora S, Lang A H, Helou B, et al. PointPainting: sequential fusion for 3D object detection[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Seattle, WA, USA, 2020: 4603-4611. |
| [10] | 李昌财, 陈刚, 侯作勋, 等. 自动驾驶中的三维目标检测算法研究综述[J]. 中国图象图形学报, 2024, 29(11): 3238-3264. |
| LI Changcai, CHEN Gang, HOU Zuoxun, et al. Survey of 3D object detection algorithms for autonomous driving[J]. J Image Grap, 2024, 29(11): 3238-3264. (in Chinese) | |
| [11] | QI C R, SU Hao, Kaichun M, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proc IEEE Conf Comput Visi Patt Recogn. Honolulu, HI, USA, 2017: 77-85 |
| [12] | Qi C R, YI Li, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]// Proc 31st Int’l Conf Neur Info Process Syst. Long Beach, California, USA, 2017: 5105-5114. |
| [13] | SHI Shaoshuai, WANG Xiaogang, LI Hongsheng. PointRCNN:3D object proposal generation and detection from point cloud[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Long Beach, CA, USA, 2019: 770-779. |
| [14] | YANG Zetong, SUN Yanan, LIU Shu, et al. 3DSSD: Point-based 3D single stage object detector[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Seattle, WA, USA, 2020: 11037-11045. |
| [15] | ZHOU Yin, Tuzel O. VoxelNet: End-to-end learning for point cloud based 3D object detection[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Salt Lake City, UT, USA, 2018: 4490-4499. |
| [16] |
YAN Yan, MAO Yuxing, LI Bo. SECOND: Sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): 3337.
doi: 10.3390/s18103337 URL |
| [17] | Graham B, Engelcke M, Van D M L. 3D semantic segmentation with submanifold sparse convolutional networks[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Salt Lake City, UT, USA, 2018: 9224-9232. |
| [18] | Lang A H, Vora S, Caesar H, et al. PointPillars: Fast encoders for object detection from point clouds[C]// Proc IEEE/CVF Conf Comput Visi Patt Recogn. Long Beach, CA, USA, 2019: 770-779. |
| [19] | 伍新月, 惠飞, 金鑫. 基于GCR-PointPillars的点云三维目标检测[J]. 现代电子技术, 2024, 47(11): 168-174. |
| WU Xinyue, HUI Fei, JIN Xin. 3D object detection in point cloud based on GCR-PointPillars[J]. Modern Elect Tech, 2024, 47(11): 168-174. | |
| [20] | 周昊, 齐洪钢, 邓永强, 等. 融合点云深度信息的3D目标检测与分类[J]. 中国图象图形学报, 2024, 29(8): 2399-2412. |
| ZHOU Hao, QI Honggang, DENG Yongqiang, et al. 3D object detection and classification combined with point cloud depth information[J]. J Image Graph, 2024, 29(8): 2399-2412. (in Chinese) | |
| [21] | 汤新华, 代道文, 陈熙源, 等. 基于PointPillars的改进三维目标检测算法[J]. 仪器仪表学报, 2024, 45(9): 260-269. |
| TANG Xinhu, DAI Daowen, CHEN Xiyuan, et al. Improved three-dimensional object detection algorithm based on PointPillars[J]. Chin J Sci Inst, 2024, 45(9): 260-269. (in Chinese) | |
| [22] | 王量子, 黄妙华, 刘若璎, 等. 改进PointPillars和Transformer的路侧两阶段三维目标检测算法[J]. 激光与光电子学进展, 2024, 61(18): 413-422. |
| WANG Liangzi, HUANG Miaohua, LIU Ruoying, et al. Improved Two-Stage 3D object detection algorithm for roadside scenes with enhanced pointpillars and transformer[J]. Lase Optoelect Prog, 2024, 61(18): 413-422. (in Chinese) | |
| [23] | SHI Guangsheng, LI Ruifeng, MA Chao. PillarNet:Real-time and high-performancepillar-based 3D object detection[C]// Proc 2022 Europ Conf Comput Visi. Tel Aviv, Israel, 22022: 35-52. |
| [24] | ZHOU Sifan, TIAN Zhi, CHU Xiangxiang, et al. FastPillars: A deployment-friendly pillar-based 3D detector[J]. ArXiv: 2302.02367, 2023. |
| [25] | 杨庆鑫, 孔德明, 陈晶, 等. 基于密度聚类和双重注意力机制的PointPillars改进方法[J]. 激光与光电子学进展, 2025, 62(10): 114-122. |
| YANG Qingxin, KONG Deming, CHEN Jing, et al. Enhancing pointpillars three-dimensional object detection with density clustering and dual attention mechanisms[J]. Lase Optoelect Prog, 2025, 62(10): 114-122. (in Chinese) | |
| [26] | Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]// Proc IEEE Conf Comput Visi Patt Recogn. Providence, RI, 2012: 3354-3361. |
| [1] | ZHENG Xunjia, CAO Zeyi, CHEN Xing, LIU Hui, GAO Jianjie. Trajectory tracking control based on adaptive prediction time-domain MPC [J]. Journal of Automotive Safety and Energy, 2025, 16(5): 773-783. |
| [2] | OUYANG Delin, QIU Yifan, WANG Yingchen, YANG Liang, MIN Haigen, WANG Wenjun, LI Guofa. End-to-end decision-making model for multi-task autonomous driving [J]. Journal of Automotive Safety and Energy, 2025, 16(4): 610-619. |
| [3] | LI Guofa, OUYANG Delin, CHEN Chen, NIE Binging, ZHANG Wei, YU Huili, Liu Bin, ZHANG Qiang, WANG Wenjun, CHENG Bo, LI Shengbo. Review on driving risk monitoring and intervention technologies [J]. Journal of Automotive Safety and Energy, 2025, 16(2): 181-196. |
| [4] | HU Zhilong, PEI Xiaofei, ZHOU Honglong, WEI Weiran. Risk-sensitive hierarchical reinforcement learning decision-making for autonomous vehicles [J]. Journal of Automotive Safety and Energy, 2025, 16(2): 326-333. |
| [5] | YANG Junru, ZHENG Sifa, XU Shucai, TIAN Ye, SUN Jian, SUN Chuan, LI Haoran. Design and research of an automated parking evaluation tool based on the OnSite platform [J]. Journal of Automotive Safety and Energy, 2025, 16(2): 334-343. |
| [6] | CAO Liling, LIU Junli, JIN Shengye, CAO Shouqi, ZHOU Guofeng. Design of a remote multidimensional information real time interaction system for autonomous driving [J]. Journal of Automotive Safety and Energy, 2024, 15(6): 934-942. |
| [7] | LIU Yang, ZHAN Jiahao, LI Shen, LI Xiaopeng, CHEN Jun. Future of autonomous driving: Single autonomous driving and intelligent vehicle-infrastructure collaboration systems [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 611-633. |
| [8] | QU Guangyue, YANG Lan, YUAN Meng, FANG Shan, LIU Songyan. A multimodal trajectory prediction method of pedestrians at signalized intersections for autonomous vehicles [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 689-701. |
| [9] | LIU Peng, ZHAO Kegang, LIANG Zhihao, YE Jie. Vehicle longitudinal speed planning based on deep reinforcement learning CLPER-DDPG [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 702-710. |
| [10] | GAO Kai, LIU Jian, LIU Linhong, LIU Xinyu, ZHANG Jinlai, DU Ronghua. Explainable lane change intention prediction based on LSTM-multi-head mixed attention [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 763-773. |
| [11] | ZHENG Xunjia, JIANG Junhao, LI Huilan, CHEN Xing, LIU Hui, WANG Jianqiang, GAO Jianjie. Research on transient driving risk vector modeling method under strong constraints of traffic regulations [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 774-782. |
| [12] | XIE Zhen, ZHOU Guofeng, WU Mingyu, CAO Shouqi. Research on dynamic modeling of port autonomous driving truck [J]. Journal of Automotive Safety and Energy, 2024, 15(5): 783-794. |
| [13] | ZHANG Chen, LIU Chang, ZHAO Jin, WANG Guangwei, XU Qing. Semantic segmentation of real-time LiDAR point clouds based on multi-scale self-attention [J]. Journal of Automotive Safety and Energy, 2024, 15(4): 591-601. |
| [14] | ZHANG Yongsheng, LI Yizhou, WANG Liang, XU Zhigang. Development status and challenges of vehicle terminals in intelligent and connected environments [J]. Journal of Automotive Safety and Energy, 2024, 15(3): 295-308. |
| [15] | LI Caihong, HE Chenyang, GAO Feng, CHEN Jiaxin. A dynamic clustering algorithm based on the point clouds distribution characteristics of obstacle [J]. Journal of Automotive Safety and Energy, 2024, 15(2): 261-267. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||