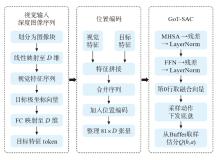
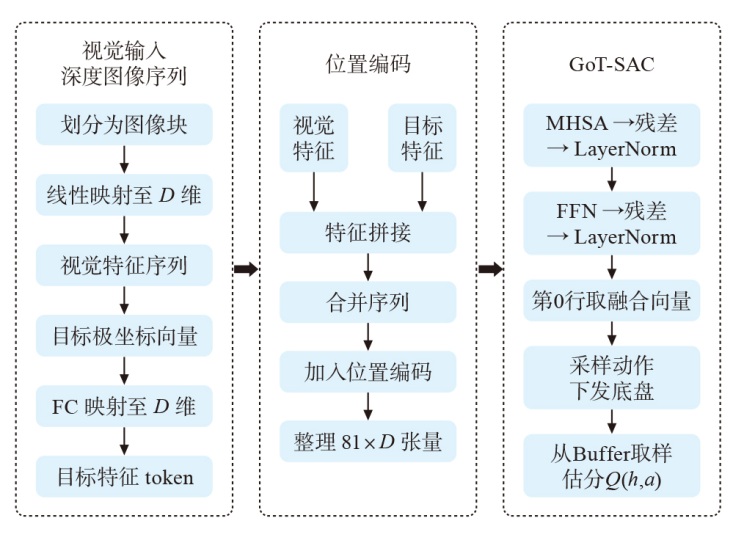
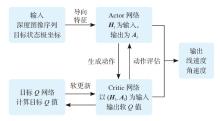
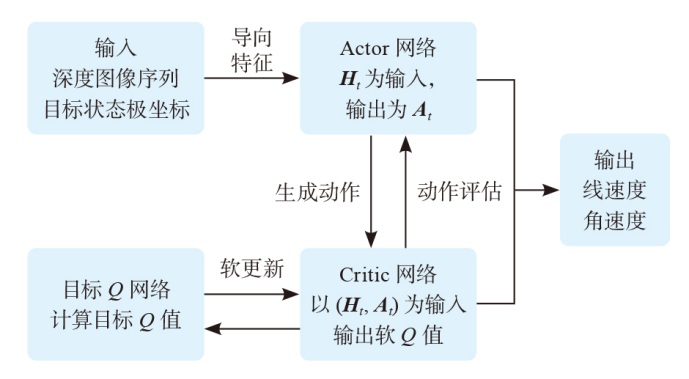
| [1] |
Balakrishnan S, Azman A D, Nisar J, et al. IoT-enabled smart warehousing with AMR robots and blockchain:A comprehensive approach to efficiency and safety[C]// Proc 3rd Int’l Conf Math Modeling Computational Sci (ICMMCS), Singapore, 2023: 261-270.
|
| [2] |
程乐平, 李欢. 智能仓储物流中机器人技术的应用与发展[J]. 信息系统工程, 2023(7): 43-46.
|
|
CHENG Leping, LI Huan. Application and development of robotic technologies in smart warehousing logistics[J]. J Info Syst Engi, 2023(7): 43-46. (in Chinese)
|
| [3] |
孔国杰, 冯时, 于会龙, 等. 无人集群系统协同运动规划技术综述[J]. 兵工学报, 2023, 44(1): 11-26.
doi: 10.12382/bgxb.2022.0930
|
|
KONG Guojie, FENG Shi, YU Huilong, et al. A survey on cooperative motion planning for unmanned swarm systems[J]. Acta Armament, 2023, 44(1): 11-26. (in Chinese)
|
| [4] |
Cruz J. Leader-follower strategies for multilevel systems[J]. IEEE Trans Autom Contr, 1978, 23(2): 244-255.
doi: 10.1109/TAC.1978.1101716
URL
|
| [5] |
Tan K H, Lewis M A. Virtual structures for high-precision cooperative mobile robotic control[C]// Proc 1996 IEEE/RSJ Int'l Conf Intell Robo Syst (IROS 1996). Osaka, Japan: IEEE, 1996: 132-139.
|
| [6] |
Balch T, Arkin R C. Behavior-based formation control for multirobot teams[J]. IEEE Trans Robot Autom, 1998, 14(6): 926-939.
doi: 10.1109/70.736776
URL
|
| [7] |
Olfati-Saber R, Murray RM. Distributed cooperative control of multiple vehicle formations using structural potential functions[C]// Proc IFAC World Congr, Barcelona, Spain: IFAC, 2002: 495-500.
|
| [8] |
Costa M M, Silva M F. A survey on path planning algorithms for mobile robots[C]// Proc 2019 IEEE Int’l Conf Autonom Robot Syst Competi (ICARSC). Piscataway: IEEE, 2019: 1-7.
|
| [9] |
Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE Trans Syst Sci Cybern, 1968, 4(2): 100-107.
doi: 10.1109/TSSC.1968.300136
URL
|
| [10] |
Dijkstra E W. A note two problems in connection with graphs[J]. Numer Math, 1959, 1(1): 269-271.
doi: 10.1007/BF01386390
URL
|
| [11] |
劳彩莲, 李鹏, 冯宇. 基于改进A*与DWA算法融合的温室机器人路径规划[J]. 农业机械学报, 2021, 52(1): 14-22.
|
|
LAO Cailian, LI Peng, FENG Yu. Greenhouse robot path planning based on improved A* and DWA fusion[J]. Trans Chin Soc Agric Engi, 2021, 52(1): 14-22. (in Chinese)
|
| [12] |
郭烈, 齐国栋, 赵一兵, 等. 融合A*与TEB算法的机器人多任务导航调度研究[J]. 华中科技大学学报(自然科学版), 2023, 51(2): 82-88.
|
|
GUO Lie, QI Guodong, ZHAO Yibing, et al. Multi-task navigation scheduling for robots via A and TEB fusion[J]. J Huazhong Univ of Sci Techn (Nat Sci Edi), 2023, 51(2): 82-88. (in Chinese).
|
| [13] |
SUN Huihui, ZHANG Weijie, YU Runxiang, et al. Motion planning for mobile robots-Focusing on deep reinforcement learning: A systematic review[J]. IEEE Access, 2021, 9: 69061-69081.
doi: 10.1109/ACCESS.2021.3076530
URL
|
| [14] |
LV Lihua, ZHANG Shujuan, DING Derong, et al. Path planning via an improved DQN-based learning policy[J]. IEEE Access, 2019, 7: 67319-67330.
doi: 10.1109/ACCESS.2019.2918703
|
| [15] |
WANG Shijie, ZHENG Xiang, CAO Yuxiang, et al. A multi-target trajectory planning of a 6-DoF free-floating space robot via reinforcement learning[C]// Int’l Conf Intell Robots Syst (IROS). IEEE, 2021: 3724-3730.
|
| [16] |
FENG Zengxi, WANG Chang, AN Jianhu, et al. Emergency fire escape path planning model based on improved DDPG algorithm[J]. J Build Engi, 2024, 95: 110090-11011.
|
| [17] |
ZHAO Feiyu, LI Dayan, WANG Zhengxu, et al. Autonomous localized path planning algorithm for UAVs based on TD3 strategy[J]. Sci Rep, 2024, 14(1): 763-785.
doi: 10.1038/s41598-024-51349-4
|
| [18] |
GFRERRER A. Geometry and kinematics of the Mecanum wheel[J]. Comput Aided Geom Des, 2008, 25(9): 784-791.
doi: 10.1016/j.cagd.2008.07.008
URL
|
| [19] |
Haastrup A I, Ofuzim O W, Oladejo J A. Kinematic analysis of omnidirectional Mecanum wheeled robot[J]. Int’l J Engi Appl Phys, 2023, 3(1): 634-644.
|
 ), 段宏伟1,3, 钟薇2, 杨路3,*(
), 段宏伟1,3, 钟薇2, 杨路3,*(