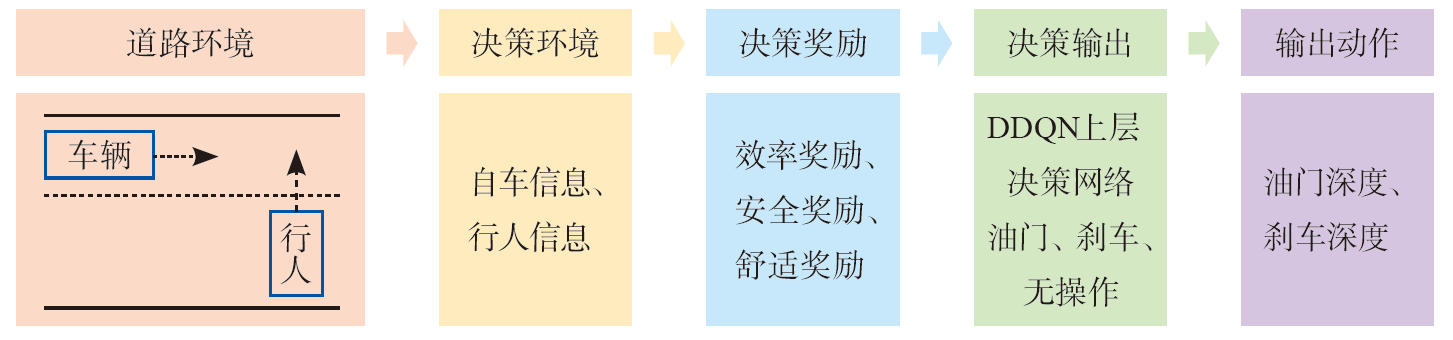
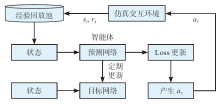
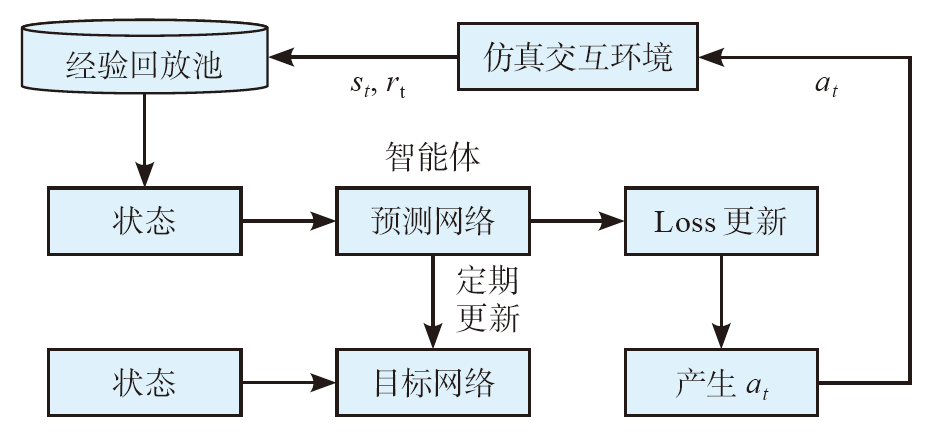
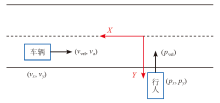
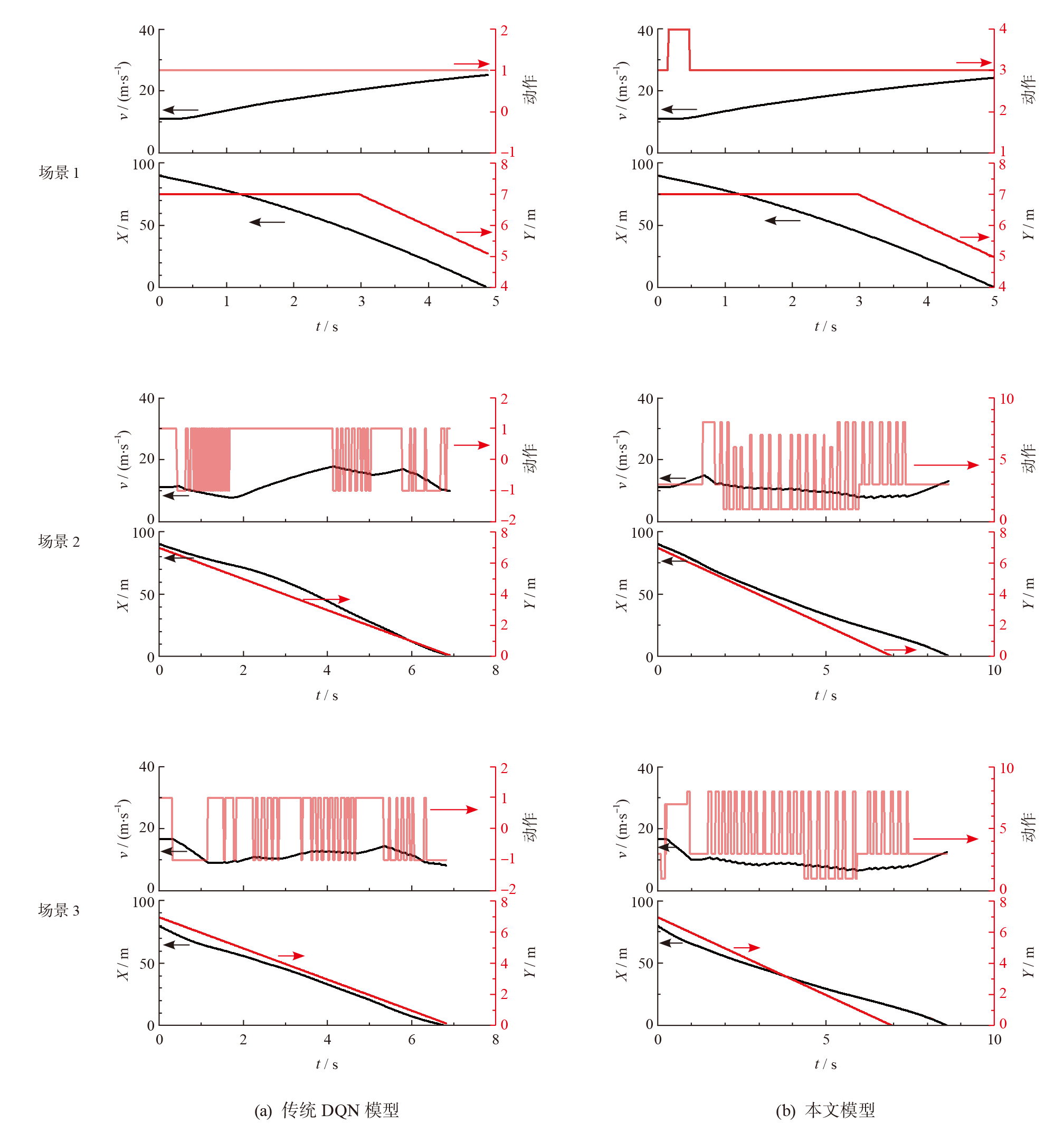
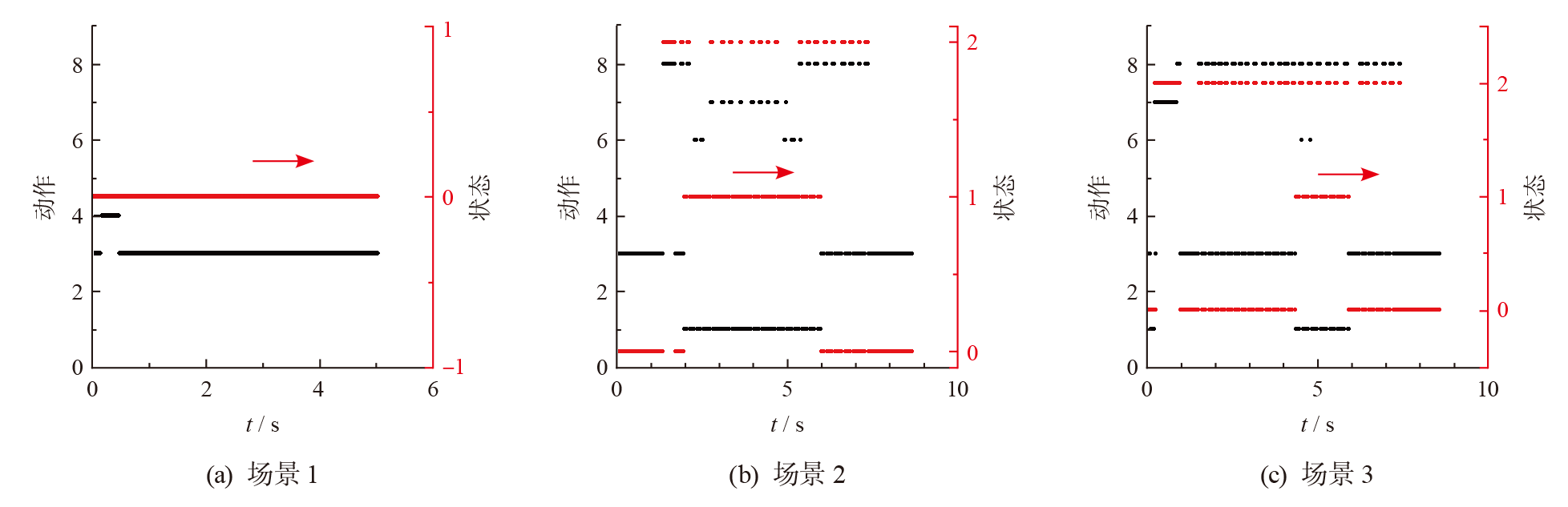
| [1] |
李克强, 戴一凡, 李升波, 等. 智能网联汽车 (ICV) 技术的发展现状及趋势[J]. 汽车安全与节能学报, 2017, 8(1): 1-14.
|
|
LI Keqiang, DAI Yifan, LI Shengbo, et al. State-of-theart and technical trends of intelligent and connected vehicles[J]. J Autom Safe Energ, 2017, 8(1): 1-14. (in Chinese)
|
| [2] |
李立, 徐志刚, 赵祥模, 等. 智能网联汽车运动规划方法研究综述[J]. 中国公路学报, 2019, 32(6): 20-33.
doi: 10.19721/j.cnki.1001-7372.2019.06.002
|
|
LI Li, XU Zhigang, ZHAO Xiangmo, et al. Review of motion planning methods of intelligent connected vehicles[J]. Chin J High Transport, 2019, 32(6): 20-33. (in Chinese)
|
| [3] |
郭烈, 孙大川, 葛平淑, 等. 复杂工况下二阶碰撞时间自动紧急制动模型[J]. 机械设计与制造, 2022, 5(1): 127-131.
|
|
GUO Lie, SUN Dachuan, GE Pingshu, et al. Automatic emergency braking model using second-order time to collision for complex condition[J]. Mach Des Manuf, 2022, 5(1): 127-131. (in Chinese)
|
| [4] |
李霖, 朱西产. 智能汽车自动紧急控制策略[J]. 同济大学学报(自然科学版), 2015, 43(11): 1735-1742.
|
|
LI Lin, ZHU Xichan. Autonomous emergency control algorithm for intelligent vehicles[J]. J Tongji Univ (Nat Sci), 2015, 43(11): 1735-1742. (in Chinese)
|
| [5] |
肖宏伟, 周睿卓, 姜晴雯, 等. 商用车视野盲区测试方法[J]. 吉林大学学报(工学版), 2022, 52(5): 1009-1015.
|
|
XIAO Hongwei, ZHOU Ruizhuo, JIANG Qingwen, et al. Test method of commercial vehicle vision blind zone[J]. J Jilin Univ (Eng Tech Ed), 2022, 52(5): 1009-1015. (in Chinese)
|
| [6] |
刘洋, 占佳豪, 李深, 等. 自动驾驶技术的未来:单车智能和智能车路协同[J]. 汽车安全与节能学报, 2024, 15(5): 611-633.
|
|
LIU Yang, ZHAN Jiahao, LI Shen, et al. Future of autonomous driving: Single autonomous driving and intelligent vehicle-infrastructure collaboration systems[J]. J Autom Safe Energ, 2024, 15(5): 611-633. (in Chinese)
|
| [7] |
金立生, 韩广德, 谢宪毅, 等. 基于强化学习的自动驾驶决策研究综述[J]. 汽车工程, 2023, 45(4): 527-540.
|
|
JIN Lisheng, HAN Guangde, XIE Xianyi, et al. Review of autonomous driving decision-Making research based on reinforcement learning[J]. Autom Engineering, 2023, 45(4): 527-540. (in Chinese)
|
| [8] |
Sallab A, Abdou M, Perot E, et al. Deep reinforcement learning framework for autonomous driving[J]. Electr Imag, 2017, 19: 70-76.
|
| [9] |
FU Yuchuan, LI Changle, YU Richard, et al. A decision making strategy for vehicle autonomous braking in emergency via deep reinforcement learning[J]. IEEE Trans Vehi Tech, 2020, 69(6): 5876-5888.
|
| [10] |
LI Junxiang, YAO Liang, XU Xin, et al. Deep reinforcement learning for pedestrian collision avoidance and human-machine cooperative driving[J]. Info Sci, 2020, 532: 110-124.
|
| [11] |
Rafiei A, Fasakhodi A O, Hajati F. Pedestrian collision avoidance using deep reinforcement learning[J]. Int’l J Autom Tech, 2022, 23(3): 613-622.
|
| [12] |
PENG Baiyu, SUN Qi, LI Shengbo E, et al. End-toend autonomous driving through dueling double deep Q-network[J]. Autom Inno, 2021, 4(3): 328-337.
|
| [13] |
LI Guofa, YANG Yifan, LI Shen, et al. Decision making of autonomous vehicles in lane change scenarios: Deep reinforcement learning approaches with risk awareness[J]. Transport Res Part C: Emerg Tech, 2021, 134: 1-18.
|
| [14] |
柳鹏, 赵克刚, 梁志豪, 等. 基于深度强化学习CLPER-DDPG的车辆纵向速度规划[J]. 汽车安全与节能学报, 2024, 15(5): 702-710.
|
|
LIU Peng, ZHAO Kegang, LIANG Zhihao, et al. Vehicle longitudinal speed planning based on deep reinforcement learning CLPER-DDPG[J]. J Autom Safe Energ. 2024, 15(5): 702-710. (in Chinese)
|
| [15] |
周恒恒, 高松, 王鹏伟, 等. 基于深度强化学习的智能车辆行为决策研究[J]. 科学技术与工程, 2024, 24(12): 5194-5203.
|
|
ZHOU Hengheng, GAO Song, WANG Pengwei, et al. Intelligent vehicles behavior decision-making based on deep reinforcement learning[J]. Sci Tech Engi, 2024, 24(12): 5194-5203. (in Chinese)
|
| [16] |
CAO Zhong, XU Shaobing, PENG Huei, et al. Confidence-aware reinforcement learning for self-driving cars[J]. IEEE Trans Intel Transport Syst, 2022, 23(7): 7419-7430.
|
| [17] |
FU Yuchuan, LI Chanle, LUAN Tomhao, et al. Graded warning for rear-end collision: An artificial intelligence-aided algorithm[J]. IEEE Trans Intel Transport Syst, 2019, 21(2): 565-579.
|
 ), 刘强1,*(
), 刘强1,*(