欢迎访问《汽车安全与节能学报》,
汽车安全与节能学报 ›› 2023, Vol. 14 ›› Issue (2): 202-211.DOI: 10.3969/j.issn.1674-8484.2023.02.007
韩玲( ), 张晖, 方若愚, 刘国鹏, 朱长盛, 迟瑞丰
), 张晖, 方若愚, 刘国鹏, 朱长盛, 迟瑞丰
收稿日期:2022-09-14
修回日期:2022-11-21
出版日期:2023-04-30
发布日期:2023-04-27
作者简介:韩玲(1984—),女(汉),吉林,副教授。E-mail:hanling@ccut.edu.cn。
基金资助:
HAN Ling(), ZHANG Hui, FANG Ruoyu, LIU Guopeng, ZHU Changsheng, CHI Ruifeng
Received:2022-09-14
Revised:2022-11-21
Online:2023-04-30
Published:2023-04-27
摘要:
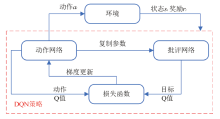
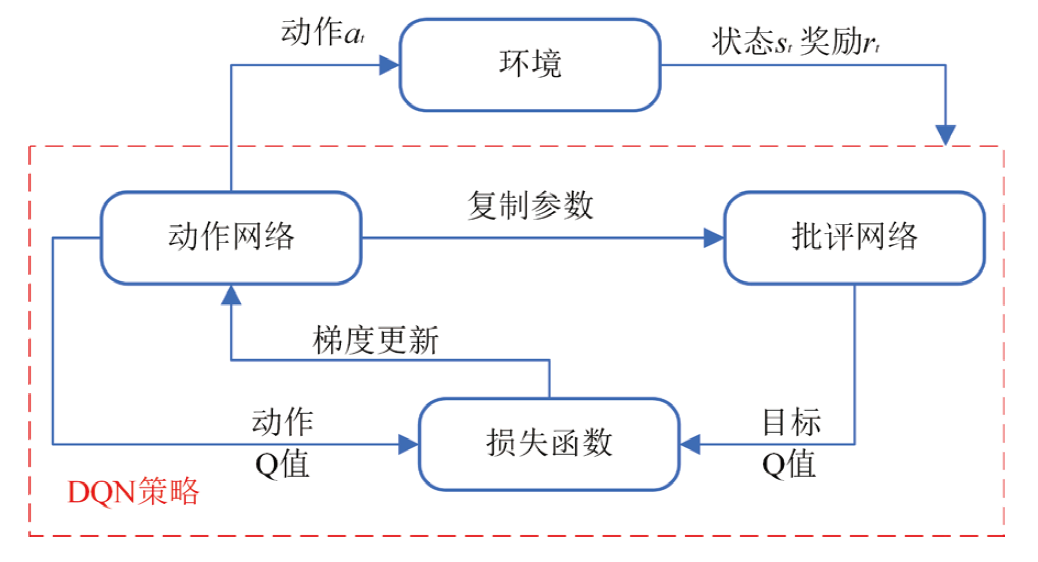
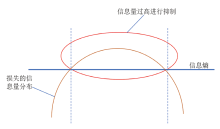
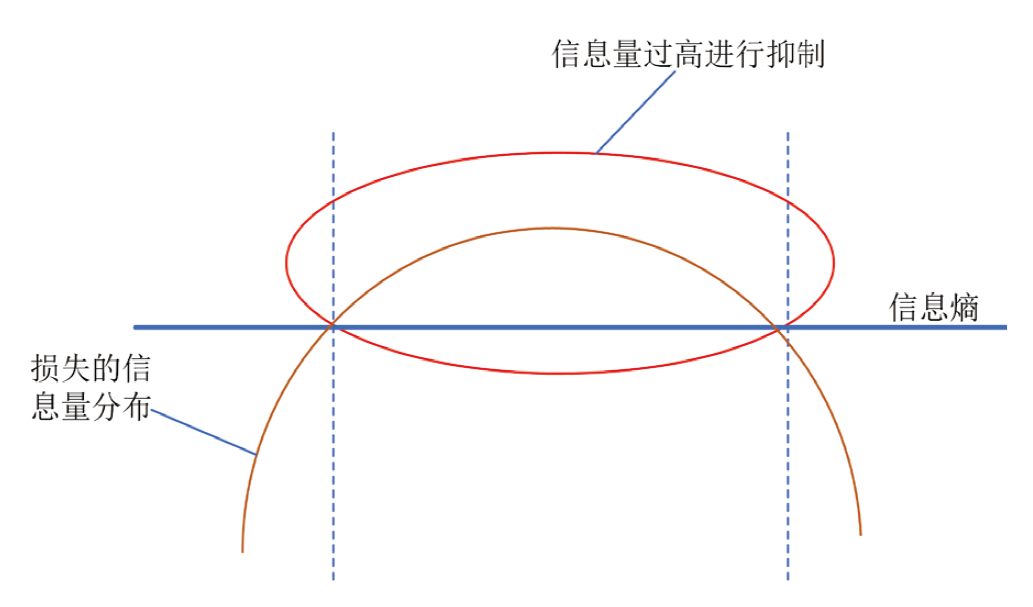
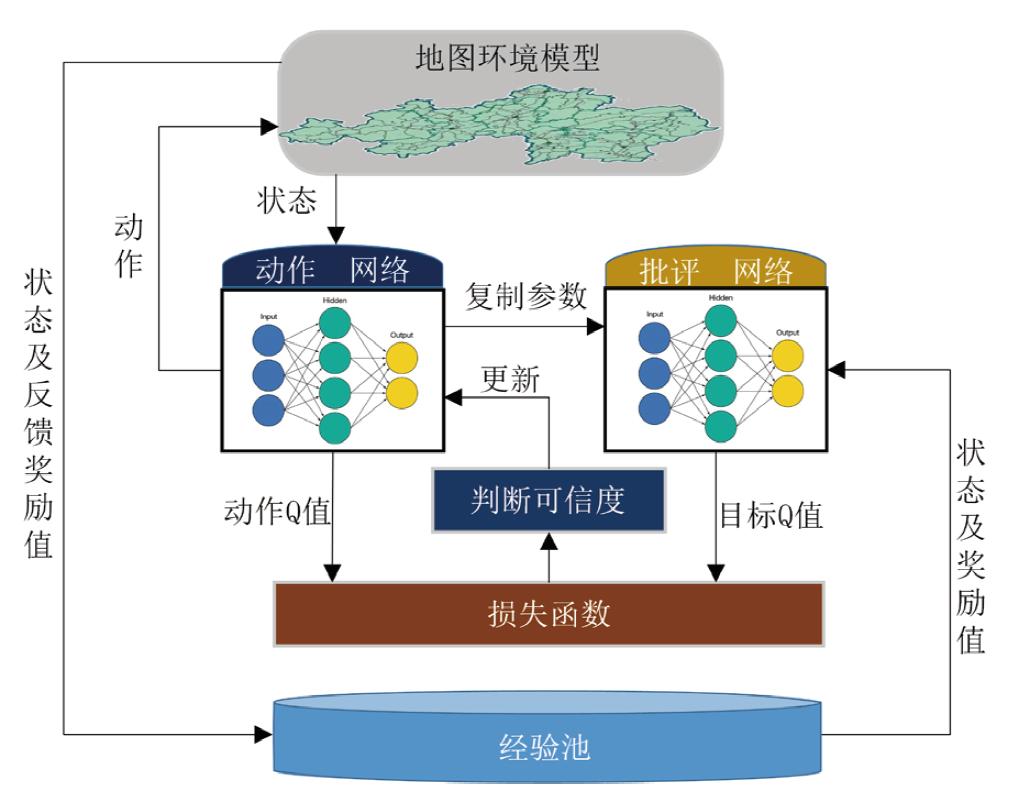
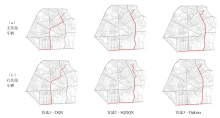
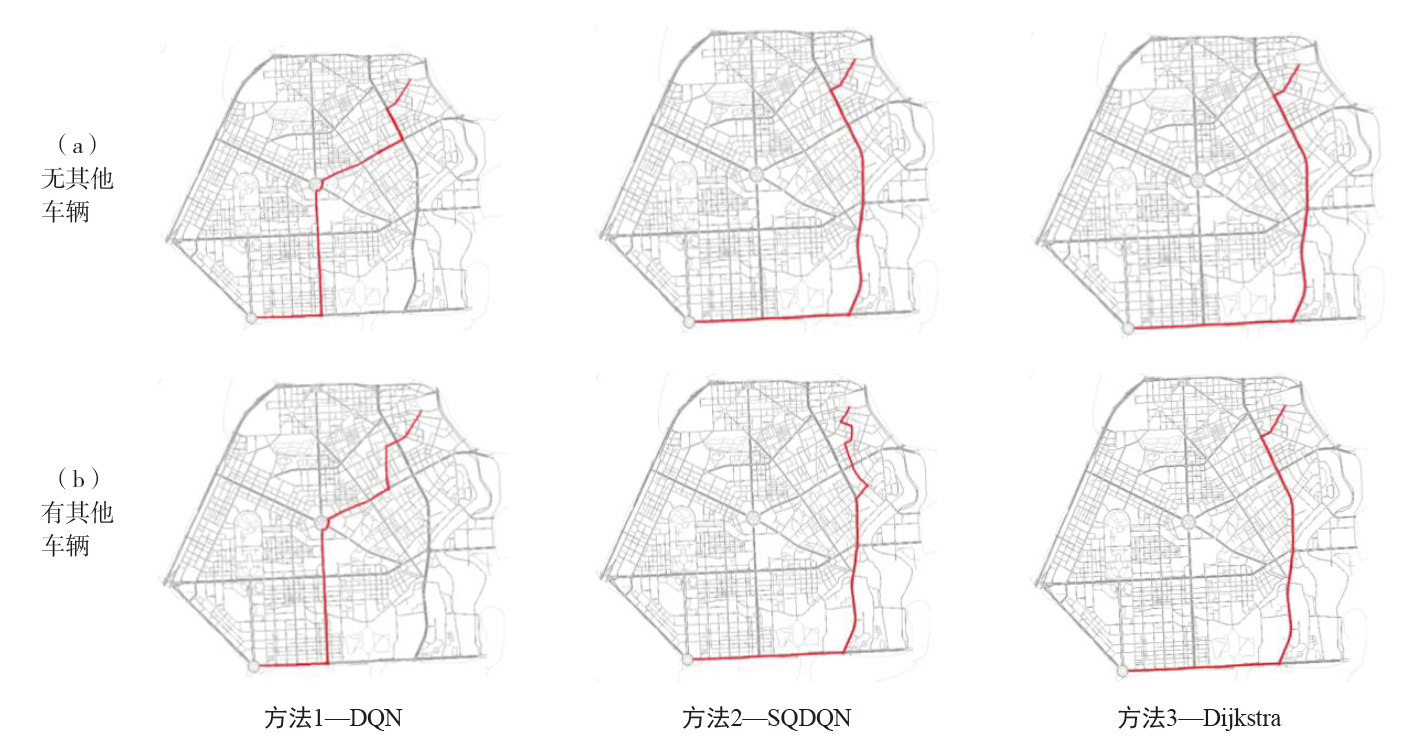
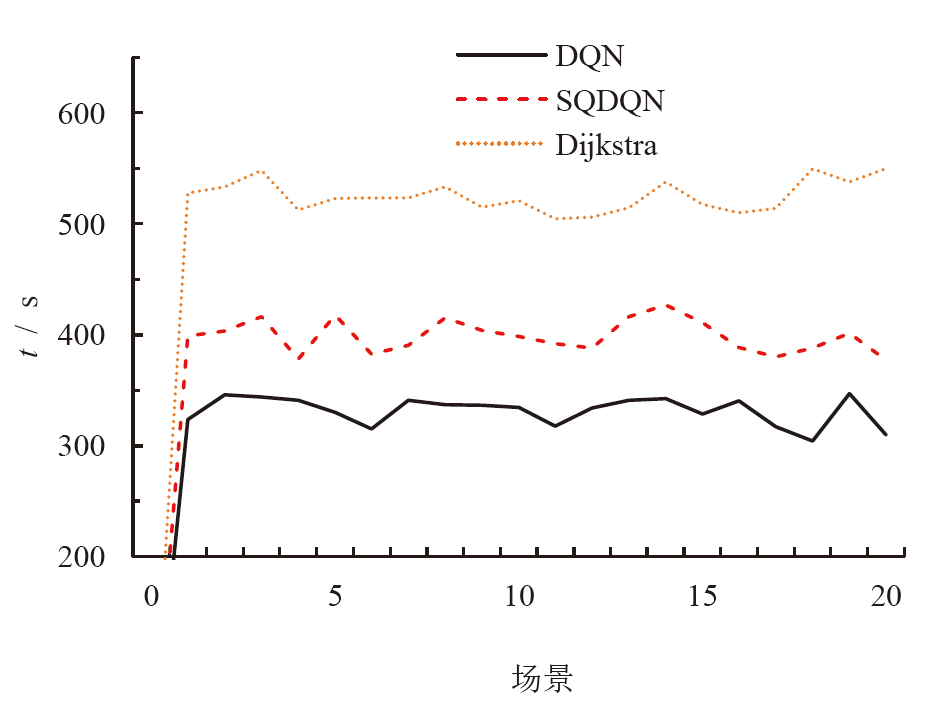
为了解决模型过度依赖与过度估计的问题,提出一种基于传统深度强化学习(DRL)的抑制过度估计深度Q网络 (SQDQN)算法,来建立全局路径规划策略。该SQDQN算法,结合深度Q网络(DQN)算法与信息熵,来抑制过度估计;借助信息熵,实时评估更新过程,来抑制DQN策略算法过度地估计损害性能;借助SQDQN算法与环境模型的交互作用,建立了获取全局路径规划策略的环境模型。结果表明:与DQN算法相比,SQDQN算法在20次实验中3次选择为更优策略;与Dijkstra传统路径规划方法相比,SQDQN算法所规划路程通行时间减少11.32%;本文的全局路径规划策略,减少了由于DQN对动作预期过高所导致的输出错误动作。
中图分类号:
韩玲, 张晖, 方若愚, 刘国鹏, 朱长盛, 迟瑞丰. 基于改进深度强化学习的全局路径规划策略[J]. 汽车安全与节能学报, 2023, 14(2): 202-211.
HAN Ling, ZHANG Hui, FANG Ruoyu, LIU Guopeng, ZHU Changsheng, CHI Ruifeng. Global path planning strategy based on an improved deep reinforcement learning[J]. Journal of Automotive Safety and Energy, 2023, 14(2): 202-211.
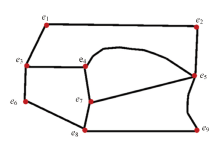
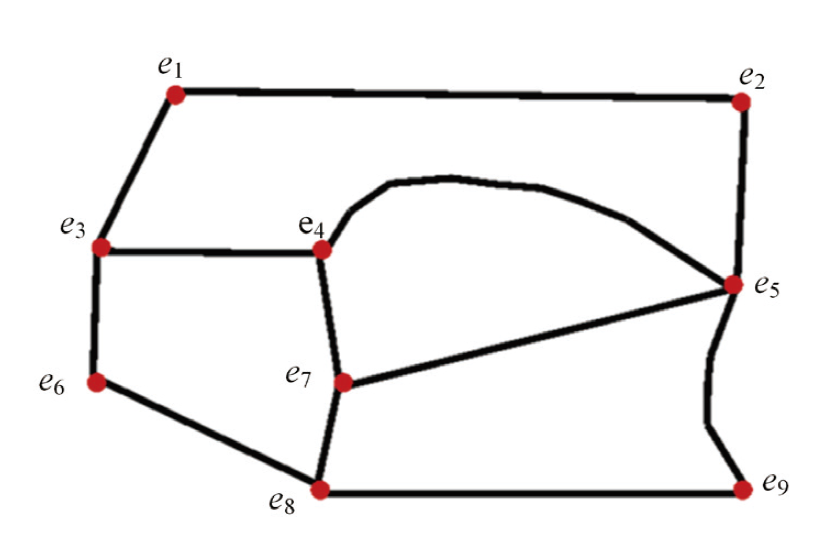
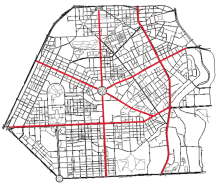
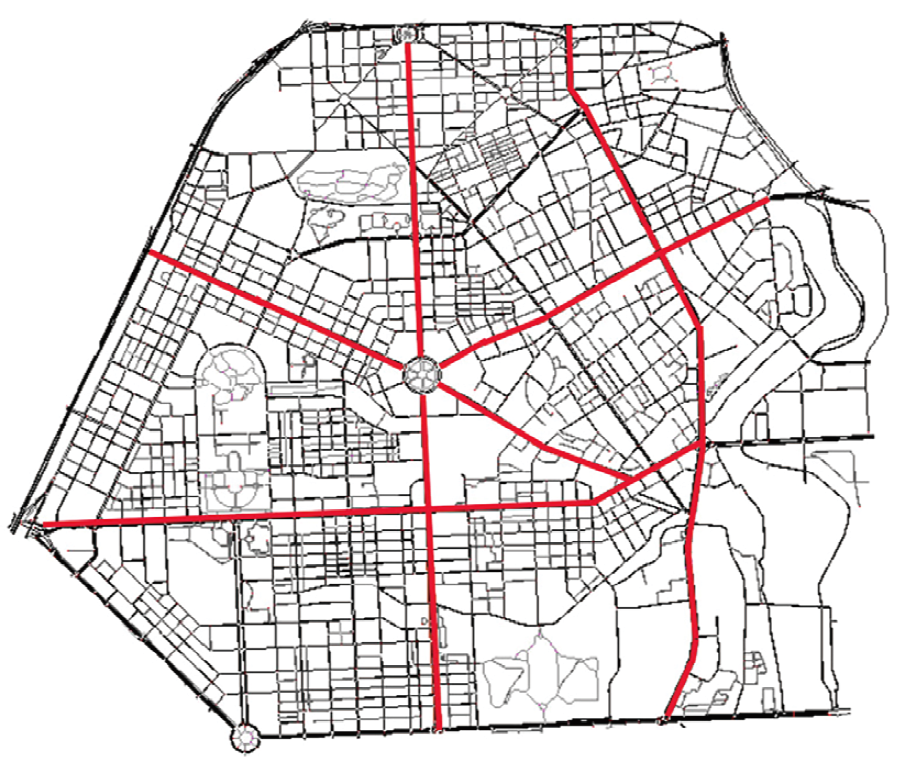
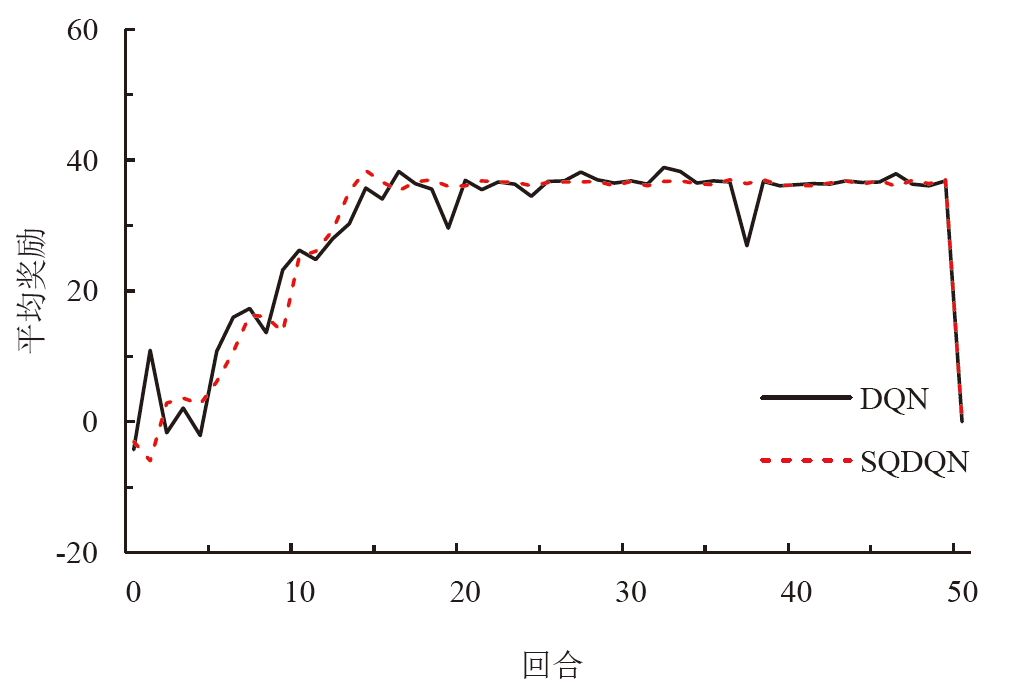
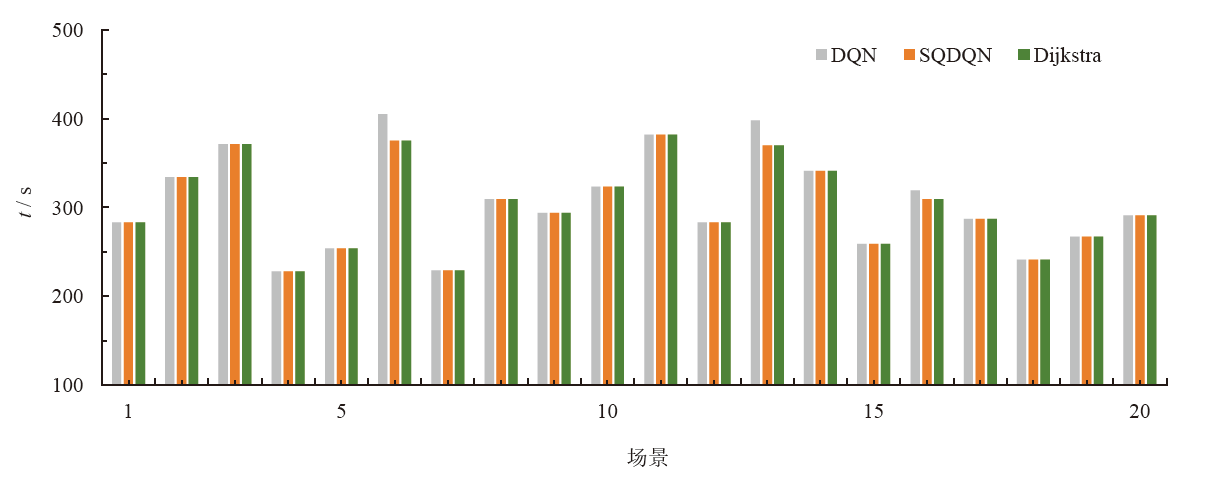
| 场景 | 通行距离 / km | ||
|---|---|---|---|
| DQN | SQDQN | Dijkstra | |
| 1 | 4.879 | 4.879 | 4.879 |
| 2 | 5.760 | 5.760 | 5.760 |
| 3 | 6.320 | 6.320 | 6.320 |
| 4 | 3.850 | 3.850 | 3.850 |
| 5 | 4.329 | 4.329 | 4.329 |
| 6 | 6.783 | 6.415 | 6.415 |
| 7 | 3.987 | 3.987 | 3.987 |
| 8 | 5.310 | 5.310 | 5.310 |
| 9 | 4.982 | 4.982 | 4.982 |
| 10 | 5.567 | 5.567 | 5.567 |
| 11 | 6.587 | 6.587 | 6.587 |
| 12 | 4.872 | 4.872 | 4.872 |
| 13 | 6.606 | 6.350 | 6.350 |
| 14 | 5.876 | 5.876 | 5.876 |
| 15 | 4.469 | 4.469 | 4.469 |
| 16 | 5.524 | 5.310 | 5.310 |
| 17 | 4.860 | 4.860 | 4.860 |
| 18 | 4.187 | 4.187 | 4.187 |
| 19 | 4.621 | 4.621 | 4.621 |
| 20 | 4.897 | 4.897 | 4.897 |
| 场景 | 通行距离 / km | ||
|---|---|---|---|
| DQN | SQDQN | Dijkstra | |
| 1 | 4.879 | 4.879 | 4.879 |
| 2 | 5.760 | 5.760 | 5.760 |
| 3 | 6.320 | 6.320 | 6.320 |
| 4 | 3.850 | 3.850 | 3.850 |
| 5 | 4.329 | 4.329 | 4.329 |
| 6 | 6.783 | 6.415 | 6.415 |
| 7 | 3.987 | 3.987 | 3.987 |
| 8 | 5.310 | 5.310 | 5.310 |
| 9 | 4.982 | 4.982 | 4.982 |
| 10 | 5.567 | 5.567 | 5.567 |
| 11 | 6.587 | 6.587 | 6.587 |
| 12 | 4.872 | 4.872 | 4.872 |
| 13 | 6.606 | 6.350 | 6.350 |
| 14 | 5.876 | 5.876 | 5.876 |
| 15 | 4.469 | 4.469 | 4.469 |
| 16 | 5.524 | 5.310 | 5.310 |
| 17 | 4.860 | 4.860 | 4.860 |
| 18 | 4.187 | 4.187 | 4.187 |
| 19 | 4.621 | 4.621 | 4.621 |
| 20 | 4.897 | 4.897 | 4.897 |
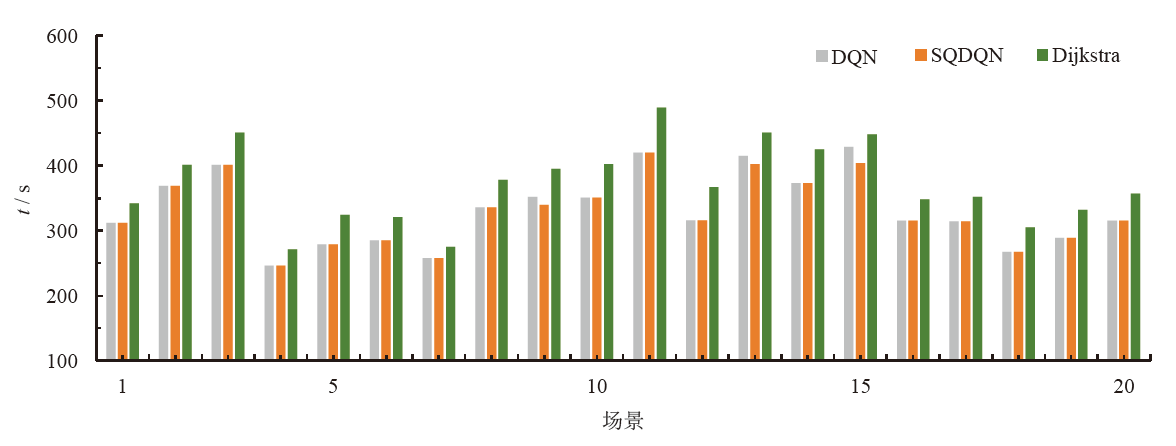
| 场景 | 通行距离 / km | 平均Q值 | ||||
|---|---|---|---|---|---|---|
| DQN | SQDQN | Dijkstra | DQN | SQDQN | ||
| 1 | 4.962 | 4.962 | 4.879 | 17.09 | 15.59 | |
| 2 | 5.837 | 5.837 | 5.760 | 18.68 | 15.30 | |
| 3 | 6.423 | 6.423 | 6.320 | 17.40 | 15.67 | |
| 4 | 3.933 | 3.933 | 3.850 | 16.96 | 15.15 | |
| 5 | 4.419 | 4.419 | 4.329 | 17.96 | 15.06 | |
| 6 | 5.420 | 5.420 | 4.469 | 20.79 | 18.03 | |
| 7 | 4.072 | 4.072 | 3.987 | 16.45 | 15.54 | |
| 8 | 5.403 | 5.403 | 5.310 | 18.50 | 15.71 | |
| 9 | 5.651 | 5.387 | 5.310 | 22.85 | 15.48 | |
| 10 | 5.657 | 5.657 | 5.567 | 18.83 | 16.00 | |
| 11 | 6.673 | 6.673 | 6.587 | 17.14 | 15.79 | |
| 12 | 4.965 | 4.965 | 4.872 | 18.61 | 15.49 | |
| 13 | 6.705 | 6.420 | 6.350 | 21.97 | 16.12 | |
| 14 | 5.978 | 5.978 | 5.876 | 18.98 | 16.01 | |
| 15 | 6.903 | 6.492 | 6.415 | 20.24 | 15.58 | |
| 16 | 5.074 | 5.074 | 4.982 | 17.49 | 15.18 | |
| 17 | 4.952 | 4.952 | 4.860 | 18.26 | 15.39 | |
| 18 | 4.320 | 4.320 | 4.187 | 17.53 | 15.69 | |
| 19 | 4.701 | 4.701 | 4.621 | 18.14 | 15.38 | |
| 20 | 5.008 | 5.008 | 4.897 | 17.50 | 14.92 | |
| 场景 | 通行距离 / km | 平均Q值 | ||||
|---|---|---|---|---|---|---|
| DQN | SQDQN | Dijkstra | DQN | SQDQN | ||
| 1 | 4.962 | 4.962 | 4.879 | 17.09 | 15.59 | |
| 2 | 5.837 | 5.837 | 5.760 | 18.68 | 15.30 | |
| 3 | 6.423 | 6.423 | 6.320 | 17.40 | 15.67 | |
| 4 | 3.933 | 3.933 | 3.850 | 16.96 | 15.15 | |
| 5 | 4.419 | 4.419 | 4.329 | 17.96 | 15.06 | |
| 6 | 5.420 | 5.420 | 4.469 | 20.79 | 18.03 | |
| 7 | 4.072 | 4.072 | 3.987 | 16.45 | 15.54 | |
| 8 | 5.403 | 5.403 | 5.310 | 18.50 | 15.71 | |
| 9 | 5.651 | 5.387 | 5.310 | 22.85 | 15.48 | |
| 10 | 5.657 | 5.657 | 5.567 | 18.83 | 16.00 | |
| 11 | 6.673 | 6.673 | 6.587 | 17.14 | 15.79 | |
| 12 | 4.965 | 4.965 | 4.872 | 18.61 | 15.49 | |
| 13 | 6.705 | 6.420 | 6.350 | 21.97 | 16.12 | |
| 14 | 5.978 | 5.978 | 5.876 | 18.98 | 16.01 | |
| 15 | 6.903 | 6.492 | 6.415 | 20.24 | 15.58 | |
| 16 | 5.074 | 5.074 | 4.982 | 17.49 | 15.18 | |
| 17 | 4.952 | 4.952 | 4.860 | 18.26 | 15.39 | |
| 18 | 4.320 | 4.320 | 4.187 | 17.53 | 15.69 | |
| 19 | 4.701 | 4.701 | 4.621 | 18.14 | 15.38 | |
| 20 | 5.008 | 5.008 | 4.897 | 17.50 | 14.92 | |
| [1] | Ibarra-Rojas O J, Delgado F. Planning, operation, and control of bus transport systems: a literature review[J]. Transp Res Part B:Methodolog, 2015, 77: 38-75. |
| [2] | KE Li, RAO Xuan, PANG Xiaobing, et al. Route Search and Planning: a survey[J]. Big Data Res, 2021, 26: 1-11. |
| [3] |
Dudeja C, Kumar P. An improved weighted sum-fuzzy Dijkstra’s algorithm for shortest path problem[J]. Soft Comput, 2022, 26(7): 3217-3226.
doi: 10.1007/s00500-022-06871-w |
| [4] |
Senbiswas R, Pal A, Werho T, et al. A graph theoretic approach to power system vulnerability identification[J]. IEEE Trans Power Syst, 2021, 36(2): 923-935.
doi: 10.1109/TPWRS.59 URL |
| [5] |
CHEN Yijing. Application of Improved dijkstra algorithm in coastal tourism route planning[J]. J Coastal Res, 2020, 106: 251-254.
doi: 10.2112/SI106-059.1 URL |
| [6] | XU Minghua, Liu Yuqing, HUANG Qilin, et al. An improved dijkstra’s shortest path algorithm for sparse network[J]. Appl Math Compu, 2007, 185(1): 247-254. |
| [7] | ZHANG Yan, LI Lingling, LIN Xiongzheng, et al. Development of path planning approach using improved a-star algorithm in agv system[J]. J Internet Tech, 2019, 20(3): 915-924. |
| [8] | 杜茂, 杨林. 基于交通时空特征的车辆全局路径规划算法[J]. 汽车安全与节能学报, 2021, 12(1): 52-61. |
| DU Mao, YANG Lin. Vehicle global path planning algorithm based on traffic space-time characteristics[J]. J Auto Safe Energ, 2021, 12(1): 52-61. (in Chinese) | |
| [9] |
SONG Rui, LIU Yuanchang, Bucknall R. Smoothed A* algorithm for practical unmanned surface vehicle path planning[J]. Appl Ocean Res, 2019, 83: 9-20.
doi: 10.1016/j.apor.2018.12.001 URL |
| [10] | Pereira F, Brasil P, Cuadros M, et al. Analysis of local trajectory planners for mobile robot with robot operating system[J]. IEEE Latin Ame Trans, 2022, 20(1): 92-99. |
| [11] | QIAN Xiaohui, ZHONG Xiaopeng. Optimal individualized multimedia tourism route planning based on ant colony algorithms and large data hidden mining[J]. Multimed Tools, 2019, 78(15): 22099-22108. |
| [12] | LI Changgeng, HUANG Xia, DING Jun, et al. Global path planning based on a bidirectional alternating search A* algorithm for mobile robots[J]. Compu Indu Eng, 2022, 168: 1-17. |
| [13] | 张瑞鑫, 王伟, 田泽, 等. 基于模型约束A*算法的无人机三维航迹规划[J]. 国外电子测量技术, 2022, 41(9): 163-169. |
| ZHANG Ruixin, WANG Wei, TIAN Ze, et al. Three dimensional path planning of uav based on model constrained A * algorithm[J]. Fore Electro Meas Tech, 2022, 41(9): 163-169. (in Chinese) | |
| [14] | JIANG Chunyan, Fu Jingfang, LIU Weiyan. Research on vehicle routing planning based on adaptive ant colony and particle swarm optimization algorithm[J]. Int’l J Intell Transp Syst Res, 2021, 19(1): 83-91. |
| [15] | 肖金壮, 余雪乐, 周刚, 等. 一种面向室内AGV路径规划的改进蚁群算法[J]. 仪器仪表学报, 2022, 43(3): 277-285. |
| XIAO Jinzhuang, YU Xuele, ZHOU Gang, et al. An improved ant colony algorithm for indoor agv path planning[J]. J Instru, 2022, 43(3): 277-285. (in Chinese) | |
| [16] | 杨立炜, 付丽霞, 王倩, 等. 多层优化蚁群算法的移动机器人路径规划研究[J]. 电子测量与仪器学报, 2021, 35(9): 10-18. |
| YANG Liwei, FU Lixia, WANG Qian, et al. Research on path planning of mobile robot based on multi-level optimization ant colony algorithm[J]. J Electro Meas Instr, 2021, 35(9): 10-18. (in Chinese) | |
| [17] | LI Xiaojing, YU Dongman. Study on an optimal path planning for a robot based on an improved ant colony algorithm[J]. Automatic Contr Compu Sci, 2019, 53(3): 236-243. |
| [18] | LOU Ping, XU Kun, JIANG Xuemei, et al. Path planning in an unknown environment based on deep reinforcement learning with prior knowledge[J]. J Intell Fuzzy Syst, 2021, 41(6): 5773-5789. |
| [19] | PAN Jie, WANG Xuesong, CHENG Yuhu, et al. Multisource transfer double dqn based on actor learning[J]. IEEE Trans Neur Networks Learn Syst, 2018 29(6): 2227-2238. |
| [20] | 李文礼, 张友松. 基于深度强化学习的车辆自主避撞决策控制模型[J]. 汽车安全与节能学报, 2021, 12(2): 201-209. |
| LI Wenli, ZHANG Yousong. Vehicle autonomous collision avoidance decision control model based on deep reinforcement learning[J]. J Auto Safe Energy 2021, 12(2): 201-209. (in Chinese) | |
| [21] |
LI Jianxin, CHEN Yiting, ZHAO Xiuniao, et al. An improved DQN path planning algorithm[J]. J Supercomput, 2022, 78(1): 616-639.
doi: 10.1007/s11227-021-03878-2 |
| [22] |
PENG Ningyezi, XI Yuliang, RAO Jinmeng. Urban multiple route planning model using dynamic programming in reinforcement learning[J]. IEEE Trans Intel Transp Syst, 2021, 23(7): 8037-8047.
doi: 10.1109/TITS.2021.3075221 URL |
| [23] | Watkins C J C H. Learning from delayed rewards[D]. Cambridge: University of Cambridge, 1989. |
| [24] | Van Hasselt H. Double Q¬learning[C]// 23rd Adv Neur Info Proc Syst (NeurIPS). Canada, Vancouver, British Columbia, 2010: 1-19. |
| [25] | Martin M L, Carro B, Esguevillas A. Application of deep reinforcement learning to intrusion detection for supervised problems[J]. Expert Syst Appl, 2020, 141: 1-15. |
| [26] | 黄琰, 张锦. 基于深度强化学习的车辆路径问题求解方法[J]. 交通运输工程与信息学报, 2022, 20(3): 114-127. |
| HUANG Yan, ZHANG Jin. Vehicle routing problem solving method based on deep reinforce-ment learning[J]. J Transp Eng Info, 2022, 20(3): 114-127. (in Chinese) |
| [1] | 李文礼, 任勇鹏, 肖凯文, 孙圆圆. 行人过街模拟及车辆右转避障路径规划方法[J]. 汽车安全与节能学报, 2024, 15(1): 99-110. |
| [2] | 张宏, 于海亮, 郑赞, 袁胜东, 熊国强. 基于数字孪生的道路交叉口建模与应用[J]. 汽车安全与节能学报, 2023, 14(1): 55-61. |
| [3] | 孙超, 刘波, 孙逢春. 新能源汽车节能规划与控制技术研究综述[J]. 汽车安全与节能学报, 2022, 13(4): 593-616. |
| [4] | 李平飞, 金思雨, 胡文浩, 高立, 车瑶栎, 谭正平, 董小飞. 用于自动驾驶仿真测试的车—车事故场景复杂度评价[J]. 汽车安全与节能学报, 2022, 13(4): 697-704. |
| [5] | 李文礼, 肖凯文, 任勇鹏, 李超, 易帆. 行人过街场景下车辆避障路径规划与控制方法[J]. 汽车安全与节能学报, 2022, 13(3): 489-501. |
| [6] | 郑阳俊, 贺帅, 帅志斌, 李建秋, 盖江涛, 李勇, 张颖, 李国辉. 基于DRL的四轮独立驱动电动车辆的侧向车速估计[J]. 汽车安全与节能学报, 2022, 13(2): 309-316. |
| [7] | 李耀华, 范吉康, 刘洋, 何杰, 李泽田, 潘绍飞. 自适应双时域参数MPC的智能车辆路径规划与跟踪控制[J]. 汽车安全与节能学报, 2021, 12(4): 528-539. |
| [8] | 杜茂, 杨林, 金悦, 涂家毓. 基于交通时空特征的车辆全局路径规划算法[J]. 汽车安全与节能学报, 2021, 12(1): 52-61. |
| [9] | 李国法,陈耀昱,吕辰, 陶达,曹东璞,成波 . 智能汽车决策中的驾驶行为语义解析关键技术[J]. JASE, 2019, 10(4): 391-412. |
| [10] | 李学鋆. 基于UTMD 的汽车自动驾驶的路径规划寻优算法[J]. JASE, 2018, 9(4): 449-455. |
| [11] | 魏祥民, 严明月, 汪䶮, 等. 基于路面识别的汽车紧急避撞控制算法[J]. JASE, 2017, 08(04): 359-366. |
| [12] | 朱西产,刘智超,李霖. 基于车辆与行人危险工况的转向避撞控制策略[J]. 汽车安全与节能学报, 2015, 6(03): 217-223. |
| [13] | 谢伯元,李克强,王建强, 赵树连. “三网融合”的车联网概念及其在汽车工业中的应用[J]. 汽车安全与节能学报, 2013, 4(4): 348-355. |
| [14] | 周晶, 彭晖. 基于伺服环动力学的自适应巡航控制系统串行稳定性研究[J]. 汽车安全与节能学报, 2010, 1(1): 30-39. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||