欢迎访问《汽车安全与节能学报》,
汽车安全与节能学报 ›› 2022, Vol. 13 ›› Issue (4): 705-717.DOI: 10.3969/j.issn.1674-8484.2022.04.012
冯耀1( ), 景首才1,3,*(), 惠飞1, 赵祥模1, 刘建蓓2,3
), 景首才1,3,*(), 惠飞1, 赵祥模1, 刘建蓓2,3
收稿日期:2021-11-27
修回日期:2022-07-18
出版日期:2022-12-31
发布日期:2023-01-01
通讯作者:
景首才
作者简介:*景首才 (1991—),男 (汉),甘肃,讲师。E-mail:scjing@che.edu.cn。基金资助:
FENG Yao1(), JING Shoucai1,3,*(), HUI Fei1, ZHAO Xiangmo1, LIU Jianbei2,3
Received:2021-11-27
Revised:2022-07-18
Online:2022-12-31
Published:2023-01-01
Contact:
JING Shoucai
摘要:
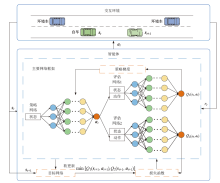
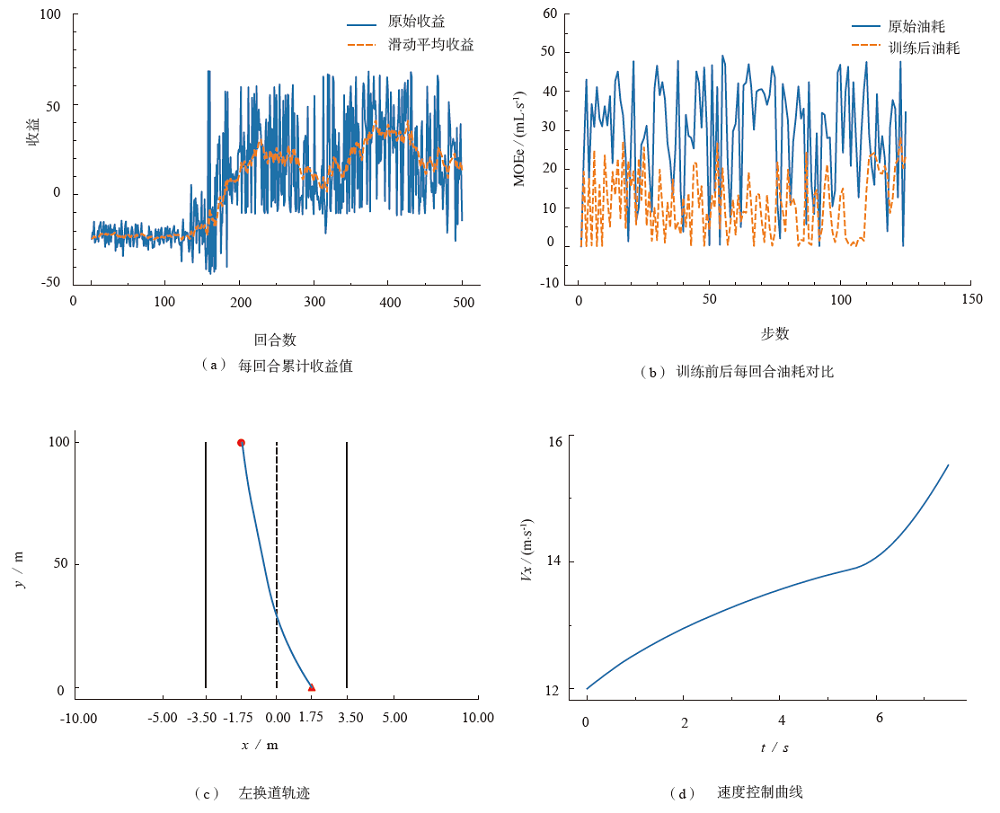
以提高智能网联车辆换道安全和效率,降低燃油消耗为目的,该文提出了一种基于深度强化学习的智能网联车辆(ICV)换道轨迹规划方法。分析复杂交通场景智能网联车辆换道功能需求,设计了分层式智能网联车辆换道轨迹规划架构;兼顾车辆安全和换道效率,设计了基于完全信息纯策略博弈的换道行为决策模型;解耦车辆纵横向运动状态,构造了以燃油消耗和乘客舒适度为目标的联合优化函数,提出了基于双延迟深度确定性策略梯度(TD3)的智能网联车辆纵横向换道轨迹规划方法,得到了车辆纵横向优化换道轨迹,并利用搭建的3个典型换道仿真场景,验证了算法的有效性。结果表明:与深度确定性策略梯度(DDPG)算法相比,提出的方法在左换道和右换道实验中的训练效率平均提升了约10.5%,平均油耗分别减少了65%和44%,而且单步轨迹规划时间在10 ms内,能够实时获取安全、节能、舒适的换道轨迹。
中图分类号:
冯耀, 景首才, 惠飞, 赵祥模, 刘建蓓. 基于深度强化学习的智能网联车辆换道轨迹规划方法[J]. 汽车安全与节能学报, 2022, 13(4): 705-717.
FENG Yao, JING Shoucai, HUI Fei, ZHAO Xiangmo, LIU Jianbei. Deep reinforcement learning-based lane-changing trajectory planning method of intelligent and connected vehicles[J]. Journal of Automotive Safety and Energy, 2022, 13(4): 705-717.
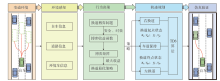
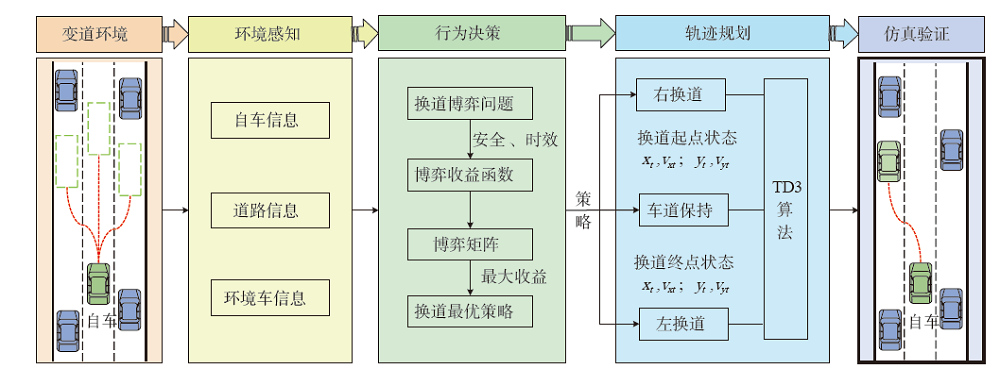
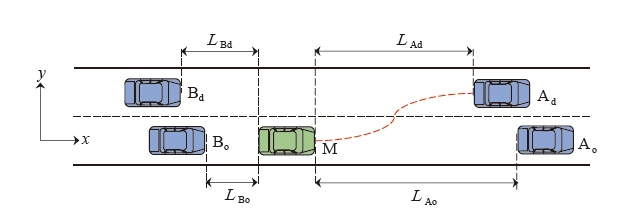
| 目标车道车辆 | 换道车辆M | |
|---|---|---|
| m1(换道) | m2(不换道) | |
| di1(允许) | [RM (di1, m1), RD (di1, m1)] | [RM (di1, m2), RD (di1, m2)] |
| di2(拒绝) | [RM (di2, m1), RD (di2, m1)] | [RM (di2, m2), RD (di2, m2)] |
| 目标车道车辆 | 换道车辆M | |
|---|---|---|
| m1(换道) | m2(不换道) | |
| di1(允许) | [RM (di1, m1), RD (di1, m1)] | [RM (di1, m2), RD (di1, m2)] |
| di2(拒绝) | [RM (di2, m1), RD (di2, m1)] | [RM (di2, m2), RD (di2, m2)] |
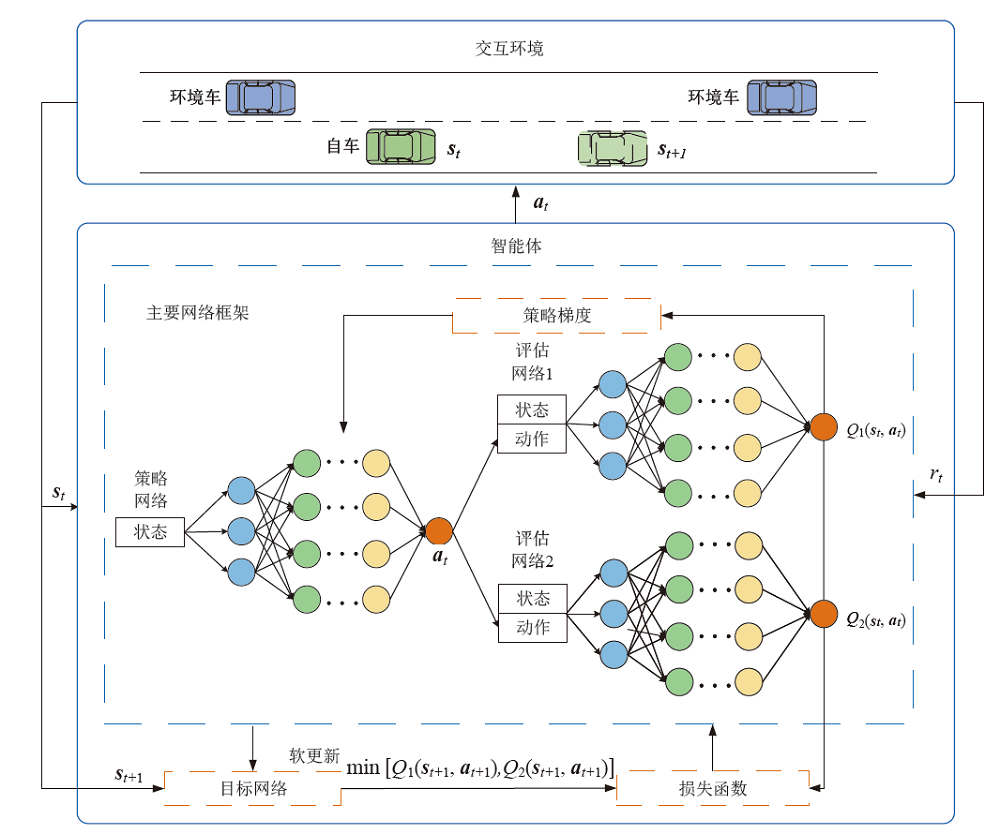
| 1 Initialization parameters: μφ、 Qθ1、 Qθ2、 μφ′、 Qθ1′、 Qθ2′、ReplayBuffer、T |
| 2 for i in T do: |
| 3 st = env.reset() |
| 4 if not done then: |
| 5 at = μφ(st) +ε, ε∈N(0, σ) |
| 6 st+1, rt, done = env.reset(at) |
| 7 ReplayBuffer.append(st, at, rt, st+1, done) |
| 8 sampleBatch (N) |
| 9 at+1 = μφ′(st+1) +ε, ε∈clip[N(0, σ), -c, c] |
| 10 $Q_{\text {targ }}=r+\gamma \min _{i=1,2} Q_{\theta i}^{\prime}\left(\boldsymbol{s}_{t+1}, \boldsymbol{a}_{t+1}\right)$ |
| 11 update Critic: $Loss =1 / N * \sum_{t=1}^{N}\left\{Q_{\text {targ }}-Q_{\theta i}\left[s_{\mathrm{t}}, \mu_{\varphi}\left(s_{\mathrm{t}}\right)\right]^{2}\right\}, i=1,2$ |
| 12 update Actor every 2 steps: $\nabla_{\varphi} J(\varphi)=\nabla_{\varphi} 1 / N * \sum_{i=1}^{N} Q_{\theta}\left[s_{\mathrm{t}}, \mu_{\varphi}\left(s_{\mathrm{t}}\right)\right]$ |
| 13 update target network, τ∈(0,1) |
| 14 $\varphi^{\prime}=\tau \varphi+(1-\tau) \varphi^{\prime}$ |
| 15 $\theta_{i}^{\prime}=\tau \theta_{i}+(1-\tau) \theta_{i}^{\prime}, i=1,2$ |
| 16 end if |
| 17 end for |
| 1 Initialization parameters: μφ、 Qθ1、 Qθ2、 μφ′、 Qθ1′、 Qθ2′、ReplayBuffer、T |
| 2 for i in T do: |
| 3 st = env.reset() |
| 4 if not done then: |
| 5 at = μφ(st) +ε, ε∈N(0, σ) |
| 6 st+1, rt, done = env.reset(at) |
| 7 ReplayBuffer.append(st, at, rt, st+1, done) |
| 8 sampleBatch (N) |
| 9 at+1 = μφ′(st+1) +ε, ε∈clip[N(0, σ), -c, c] |
| 10 $Q_{\text {targ }}=r+\gamma \min _{i=1,2} Q_{\theta i}^{\prime}\left(\boldsymbol{s}_{t+1}, \boldsymbol{a}_{t+1}\right)$ |
| 11 update Critic: $Loss =1 / N * \sum_{t=1}^{N}\left\{Q_{\text {targ }}-Q_{\theta i}\left[s_{\mathrm{t}}, \mu_{\varphi}\left(s_{\mathrm{t}}\right)\right]^{2}\right\}, i=1,2$ |
| 12 update Actor every 2 steps: $\nabla_{\varphi} J(\varphi)=\nabla_{\varphi} 1 / N * \sum_{i=1}^{N} Q_{\theta}\left[s_{\mathrm{t}}, \mu_{\varphi}\left(s_{\mathrm{t}}\right)\right]$ |
| 13 update target network, τ∈(0,1) |
| 14 $\varphi^{\prime}=\tau \varphi+(1-\tau) \varphi^{\prime}$ |
| 15 $\theta_{i}^{\prime}=\tau \theta_{i}+(1-\tau) \theta_{i}^{\prime}, i=1,2$ |
| 16 end if |
| 17 end for |
| 网络 | 层 | 维度 | 激活函数 |
|---|---|---|---|
| Actor网络 | L1 | (s, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, a) | Tanh | |
| Critic1网络 | L1 | (s+a, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, 1) | 无 | |
| Critic2网络 | L1 | (s+a, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, 1) | 无 |
| 网络 | 层 | 维度 | 激活函数 |
|---|---|---|---|
| Actor网络 | L1 | (s, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, a) | Tanh | |
| Critic1网络 | L1 | (s+a, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, 1) | 无 | |
| Critic2网络 | L1 | (s+a, 30) | Relu |
| L2 | (30, 30) | Relu | |
| L3 | (30, 1) | 无 |
| 参数名称 | 参数值 |
|---|---|
| 训练回合数 | 500 |
| 每回合最大步数 | 200 |
| 批量大小 | 64 |
| 经验池容量 | 104 |
| 折扣系数 | 0.99 |
| Actor网络学习率 | 3×10-4 |
| Critic网络学习率 | 3 ×10-4 |
| 软更新速率 | 1×10-3 |
| 动作探索噪声 | 0.1 |
| 策略噪声 | 0.5 |
| 延迟更新频率 | 2 |
| 优化器类型 | Adam |
| 参数名称 | 参数值 |
|---|---|
| 训练回合数 | 500 |
| 每回合最大步数 | 200 |
| 批量大小 | 64 |
| 经验池容量 | 104 |
| 折扣系数 | 0.99 |
| Actor网络学习率 | 3×10-4 |
| Critic网络学习率 | 3 ×10-4 |
| 软更新速率 | 1×10-3 |
| 动作探索噪声 | 0.1 |
| 策略噪声 | 0.5 |
| 延迟更新频率 | 2 |
| 优化器类型 | Adam |
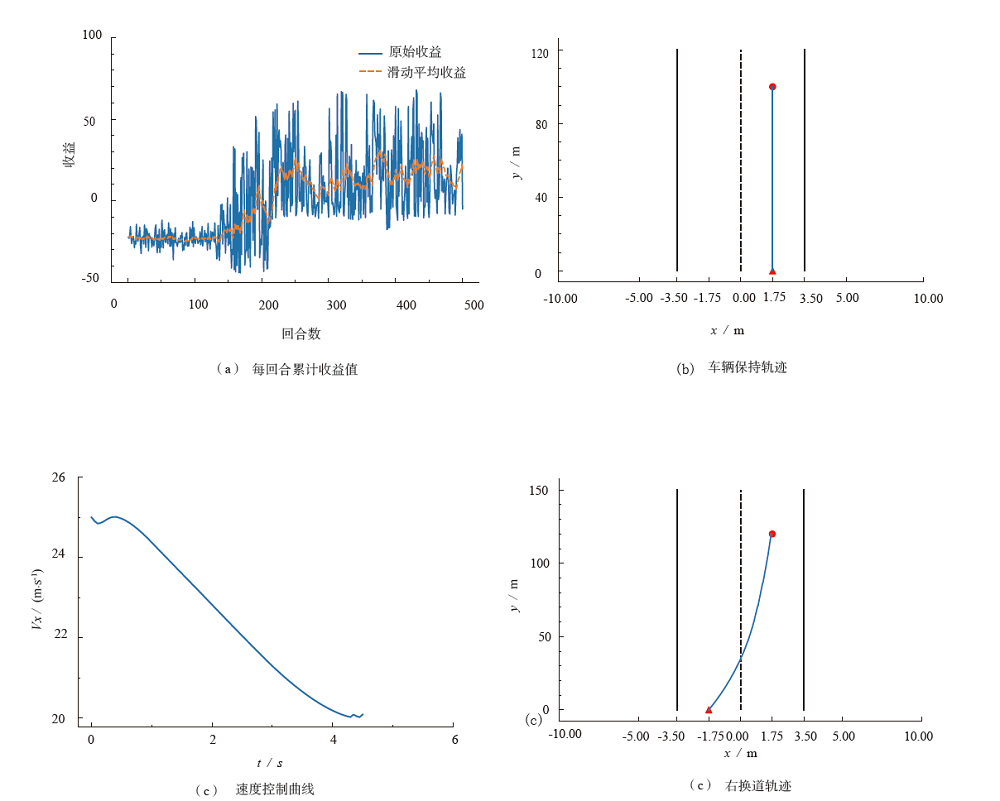
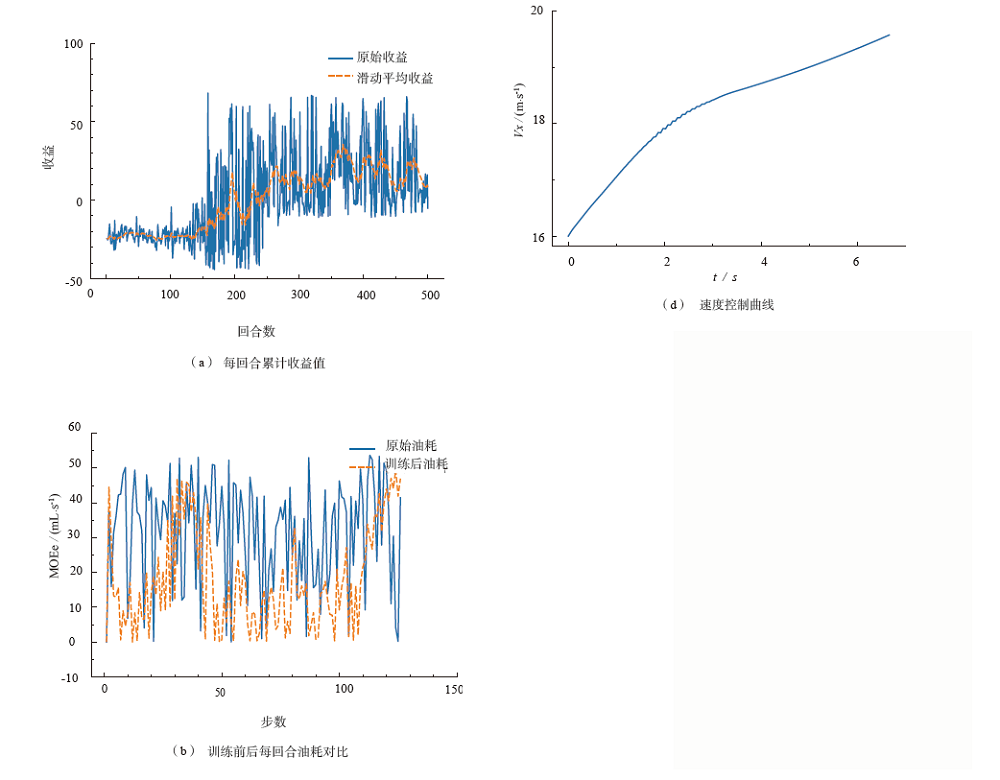

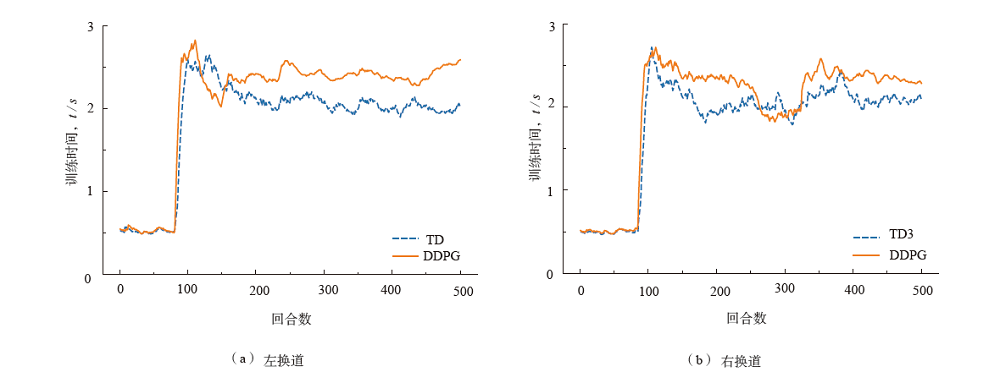
| 场景 | 算法 | 总训练时间/ s | 每回合平均训练时间 / s | 加载模型、规划时间/ s | 单步规划时间 / ms |
|---|---|---|---|---|---|
| 左换道 | TD3 | 935.27 | 1.87 | 1.23(144 step) | 8.48 |
| DDPG | 1 065.12 | 2.13 | 1.11(129 step) | 8.54 | |
| 右换道 | TD3 | 918.40 | 1.84 | 1.26(132 step) | 9.47 |
| DDPG | 1 012.24 | 2.02 | 1.17(122 step) | 9.51 |
| 场景 | 算法 | 总训练时间/ s | 每回合平均训练时间 / s | 加载模型、规划时间/ s | 单步规划时间 / ms |
|---|---|---|---|---|---|
| 左换道 | TD3 | 935.27 | 1.87 | 1.23(144 step) | 8.48 |
| DDPG | 1 065.12 | 2.13 | 1.11(129 step) | 8.54 | |
| 右换道 | TD3 | 918.40 | 1.84 | 1.26(132 step) | 9.47 |
| DDPG | 1 012.24 | 2.02 | 1.17(122 step) | 9.51 |
| [1] | 李克强, 戴一凡, 李升波, 等. 智能网联汽车(ICV)技术的发展现状及趋势[J]. 汽车安全与节能学报, 2017, 8(1): 1-14. |
| LI Keqiang, DAI Yifan, LI Shengbo, et al. State-of-the-art and technical trends of intelligent and connected vehicles[J]. J Autom Safe Energ, 2017, 8(1): 1-14. (in Chinese) | |
| [2] |
李立, 徐志刚, 赵祥模, 等. 智能网联汽车运动规划方法研究综述[J]. 中国公路学报, 2019, 32(6): 20-33.
doi: 10.19721/j.cnki.1001-7372.2019.06.002 |
| LI Li, XU Zhigang, ZHAO Xiangmo, et al. Review of motion planning methods of intelligent connected vehicles[J]. Chin J High Transport, 2019, 32(6): 20-33. (in Chinese) | |
| [3] | ZHAO Ding, Lam H, PENG Huei, et al. Accelerated evaluation of automated vehicles safety in lane-change scenarios based on importance sampling techniques[J]. IEEE Trans Intel Transport Syst, 2017, 18(3): 595-607. |
| [4] | 卢兆麟, 李升波, Schroeder F, 等. 结合自然语言处理与改进层次分析法的乘用车驾驶舒适性评价[J]. 清华大学学报(自然科学版), 2016, 56(2): 137-143. |
| LU Zhaolin, LI Shengbo, Schroeder F, et al. Driving comfort evaluation of passenger vehicles with natural language processing and improved AHP[J]. J Tsinghua Univ (Sci Tech), 2016, 56(2): 137-143. (in Chinese) | |
| [5] | MA Liang, XUE Jianru, Kawabata K, et al. Efficient sampling-based motion planning for on-road autonomous driving[J]. IEEE Trans Intel Transport Syst, 2015, 16(4): 1961-1976. |
| [6] | Shaikh E A, Dhale A. AGV path planning and obstacle avoidance using Dijkstra’s algorithm[J]. Int’l J Appl Innov Engi Manag, 2013, 2(6): 77-83. |
| [7] | ZHANG Jing, WU Jun, SHEN Xiao, et al. Autonomous land vehicle path planning algorithm based on improved heuristic function of A-star[J]. Int’l J Advan Robo Syst, 2021, 18(5): 1-10. |
| [8] |
张卫波, 肖继亮. 改进RRT算法在复杂环境下智能车路径规划中的应用[J]. 中国公路学报, 2021, 34(3): 225-234.
doi: 10.19721/j.cnki.1001-7372.2021.03.017 |
| ZHANG Weibo, XIAO Jiliang. Application of improved RRT algorithm in intelligent vehicle path planning under complicated environment[J]. Chin J High Transport, 2021, 34(3): 225-234. (in Chinese) | |
| [9] | YOU Feng, ZHANG Ronghui, LIE Guo, et al. Trajectory planning and tracking control for autonomous lane change maneuver based on the cooperative vehicle infrastructure system[J]. Expert Syst Appl: An Int’l J, 2015, 42(14): 5932-5946. |
| [10] | Broggi A, Medici P, Zani P, et al. Autonomous vehicles control in the vislab intercontinental autonomous challenge[J]. Annu Rev Contr, 2012, 36(1): 161-171. |
| [11] | Chu K, Lee M, Sunwoo M. Local path planning for off-Road autonomous driving with avoidance of static obstacles[J]. IEEE Trans Intel Transport Syst, 2012, 13(4): 1599-1616. |
| [12] | 陈成, 何玉庆, 卜春光, 等. 基于四阶贝塞尔曲线的无人车可行轨迹规划[J]. 自动化学报, 2015, 41(3): 486-496. |
| CHEN Cheng, HE Yuqing, BU Chunguang, et al. Feasible trajectory generation for autonomous vehicles based on quartic bezier curve[J]. Acta Autom Sinica, 2015, 41(3): 486-496. (in Chinese) | |
| [13] | 徐杨, 陆丽萍, 褚端峰, 等. 无人车辆轨迹规划与跟踪控制的统一建模方法[J]. 自动化学报, 2019, 45(4): 799-807. |
| XU Yang, LU Liping, CHU Duanfeng, et al. Unified modeling of trajectory planning and tracking for unmanned vehicle[J]. Acta Autom Sinica, 2019, 45(4): 799-807. (in Chinese) | |
| [14] |
江浩斌, 施凯津, 华一丁, 等. 基于HP自适应伪谱法的智能汽车紧急变道轨迹规划与优化[J]. 中国公路学报, 2019, 32(6): 71-78.
doi: 10.19721/j.cnki.1001-7372.2019.06.007 |
| JIANG Haobin, SHI Kaijin, HUA Yiding, et al. Lane-changing trajectory planning and optimization for intelligent vehicle through HP-adaptive pseudospectral method[J]. Chin J High Transport, 2019, 32(6): 71-78. (in Chinese) | |
| [15] | Sallab A, Abdou M, Perot E, et al. Deep reinforcement learning framework for autonomous driving[J]. Electr Imag, 2017(19): 70-76. |
| [16] | FU Yuchuan, LI Changle, YU Richard, et al. A Decision-making strategy for vehicle autonomous braking in emergency via deep reinforcement learning[J]. IEEE Trans Vehi Tech, 2020, 69(6): 5876-5888. |
| [17] | Saxena D M, Bae S, Nakhaei A, et al. Driving in dense traffic with model-free reinforcement learning[J]. IEEE Int’l Conf Robot Auto, 2020(99): 5385-5392. |
| [18] | Hoel C J, Wolff K, Laine L. Automated speed and lane change decision making using deep reinforcement learning[J]. IEEE Int’l Conf Intel Transport Syst, 2018(99): 2148-2155. |
| [19] | PENG Baiyu, SUN Qi, LI Shengbo E, et al. End-to-end autonomous driving through dueling double deep Q-network[J]. Autom Innocation, 2021, 4(3): 328-337. |
| [20] | CHEN Jianyu, LI Shengbo E, Tomizuka M. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning[J]. IEEE Trans Intel Transport Syst, 2021(99): 1-11. |
| [21] | LI Guofa, YANG Yifan, LI Shen, et al. Decision making of autonomous vehicles in lane change scenarios: Deep reinforcement learning approaches with risk awareness[J]. Transport Res Part C: Emerg Tech, 2021, 134: 1-18. |
| [22] | Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J/OL]. (2015-09-09), http//arxiv.org/abs/1509.02971. |
| [23] | Fujimoto S, Hoof H V, Meger D. Addressing function approximation error in actor-critic methods[J/OL]. (2018-02-26), http//arxiv.org/abs/1802.09477. http//arxiv.org/abs/1802.09477 |
| [24] | 采国顺, 刘昊吉, 冯吉伟, 等. 智能汽车的运动规划与控制研究综述[J]. 汽车安全与节能学报, 2021, 12(3): 279-297. |
| CAI Guoshun, LIU Haoji, FENG Jiwei, et al. Review on the research of motion planning and control for intelligent vehicles[J]. J Autom Safe Energ, 2021, 12(3): 279-297. (in Chinese) | |
| [25] | CAO Zhong, XU Shaobing, PENG Huei, et al. Confidence-aware reinforcement learning for self-driving cars[J]. IEEE Trans Intel Transport Syst, 2021(99): 1-12. |
| [26] | 龚建伟, 姜岩, 徐威. 无人驾驶车辆模型预测控制[M]. 北京: 北京理工大学出版社, 2014: 5-20. |
| GONG Jianwei, JIANG Yan, XU Wei, Model Predictive Control for Self-Driving Vehicles[M]. Beijing: Institute of Technology Press, Beijing, 2014: 5-20. (in Chinese) | |
| [27] | Talebpour A, Mahmassani H S, Hamdar S H. Modeling lane-changing behavior in a connected environment: A game theory approach[J]. Transport Res Part C, 2015, 59(7): 216-232. |
| [28] | Shakarian P, Roos P, Johnson A. A review of evolutionary graph theory with applications to game theory[J]. Bio Syst, 2012, 107(2): 66-80. |
| [29] | Volodymyr M, Koray K, David S, et al. Human-level control through deep reinforcement learning[J]. Nature, 2019, 518(7540): 529-533. |
| [30] | JING Shoucai, HUI Fei, ZHAO Xiangmo, et al. Cooperative game approach to optimal merging sequence and on-ramp merging control of connected and automated vehicles[J]. IEEE Trans Intel Transport Syst, 2019 (99): 1-11. |
| [31] | Ahn K, Rakha H, Trani A, et al. Estimating vehicle fuel consumption and emissions based on instantaneous speed and acceleration levels[J]. J Transport Engi, 2002, 128(2): 182-190. |
| [1] | 李文礼, 邱凡珂, 廖达明, 任勇鹏, 易帆. 基于深度强化学习的高速公路换道跟踪控制模型[J]. 汽车安全与节能学报, 2022, 13(4): 750-759. |
| [2] | 张平, 陈一凡, 江书真, 韩毅. 高速公路上自动超车过程的轨迹规划与跟踪控制[J]. 汽车安全与节能学报, 2022, 13(3): 463-472. |
| [3] | 彭涛, 许庆, 陈强, 关志伟, 侯海晶, 王涛, 李佳林. 异构载货车辆队列高速换道分布式反馈线性化控制[J]. 汽车安全与节能学报, 2022, 13(3): 473-481. |
| [4] | 郑阳俊, 贺帅, 帅志斌, 李建秋, 盖江涛, 李勇, 张颖, 李国辉. 基于DRL的四轮独立驱动电动车辆的侧向车速估计[J]. 汽车安全与节能学报, 2022, 13(2): 309-316. |
| [5] | 刘兵, 王锦锐, 谢济铭, 陈金宏, 段国忠, 叶保权, 侯效伟, 彭博. 微观轨迹数据驱动的交织区换道概率分布模型[J]. 汽车安全与节能学报, 2022, 13(2): 333-340. |
| [6] | 魏祥民, 严明月, 汪䶮, 等. 基于路面识别的汽车紧急避撞控制算法[J]. JASE, 2017, 08(04): 359-366. |
| [7] | 杨林,胡艳青,闫斌. 基于行驶工况的插电式混合动力汽车电能消耗最优控制[J]. JASE, 2017, 08(01): 87-96. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||