欢迎访问《汽车安全与节能学报》,
汽车安全与节能学报 ›› 2025, Vol. 16 ›› Issue (4): 587-597.DOI: 10.3969/j.issn.1674-8484.2025.04.009
韩雨1( ), 陈志轩1, 王翊萱1,*(), 李春杰1, 雷伟2, 焦彦利2, 刘攀1
), 陈志轩1, 王翊萱1,*(), 李春杰1, 雷伟2, 焦彦利2, 刘攀1
收稿日期:2024-11-29
修回日期:2025-04-27
出版日期:2025-08-30
发布日期:2025-08-27
通讯作者:
*王翊萱,助理研究员。E-mail:yixuanseu@126.com。
作者简介:韩雨(1989—),男(汉),山东,副教授。E-mail:yuhan@seu.edu.cn。
基金资助:
HAN Yu1(), CHEN Zhixuan1, WANG Yixuan1,*(), LI Chunjie1, LEI Wei2, JIAO Yanli2, LIU Pan1
Received:2024-11-29
Revised:2025-04-27
Online:2025-08-30
Published:2025-08-27
摘要:
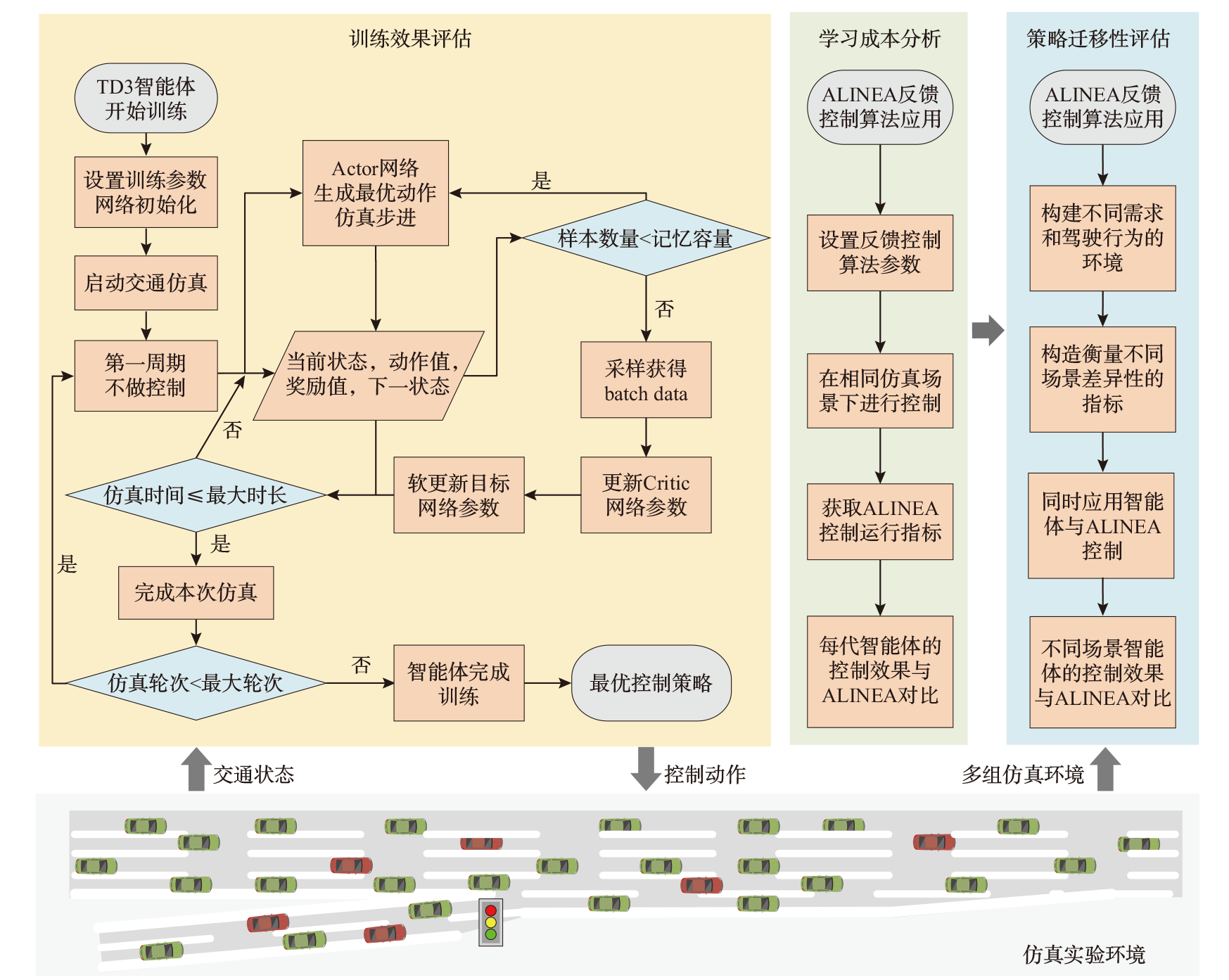
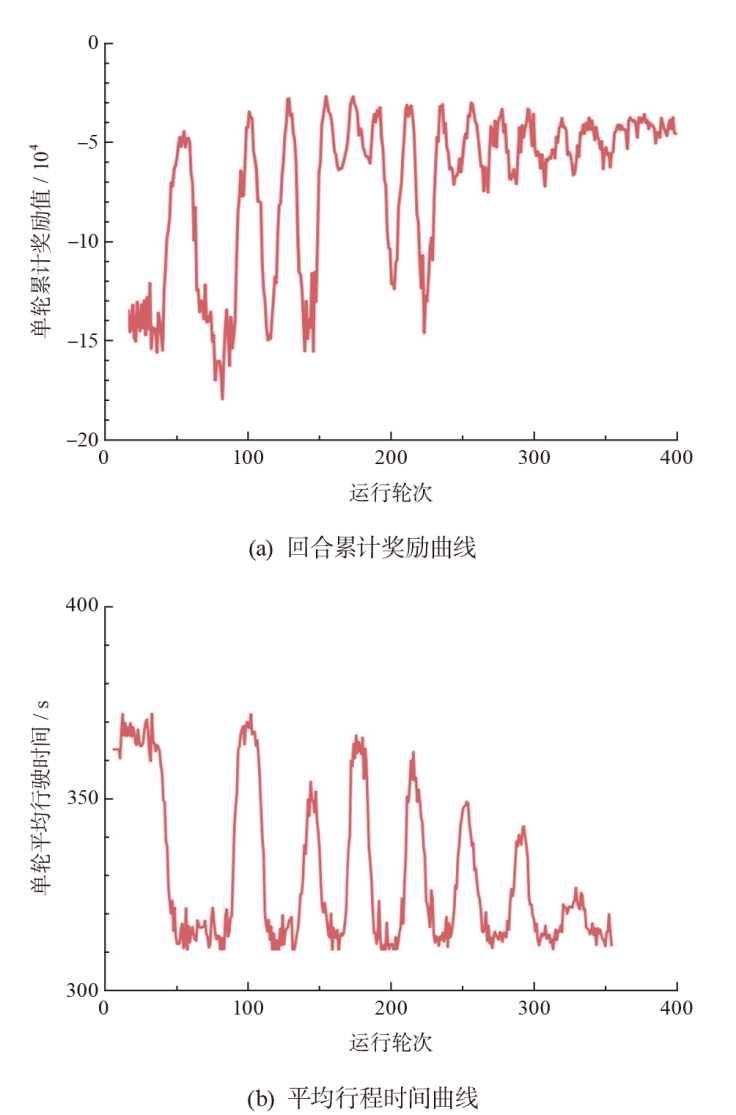
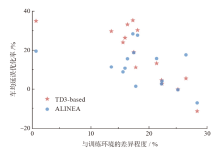
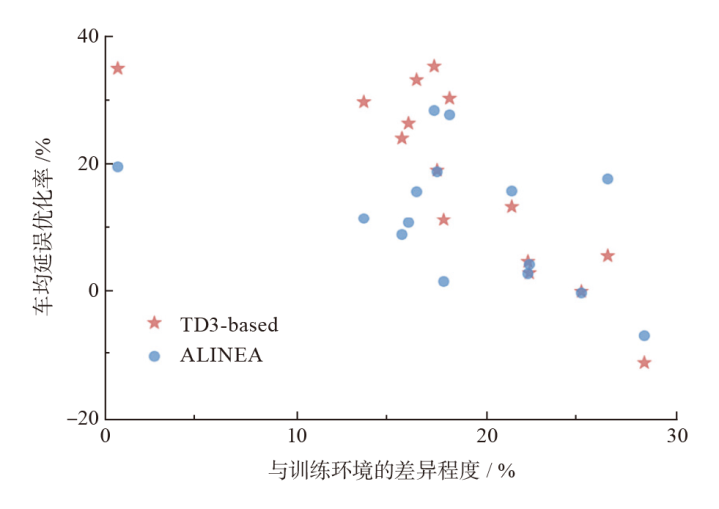
针对当前基于强化学习的匝道控制方法对策略训练中的学习成本、策略迁移性等研究不充分,导致控制策略难以在实际中应用的问题,该文提出一种匝道控制策略优化的强化学习方法,并通过大量仿真实验对方法的可移植性进行了深入研究。构建匝道控制模型,提出基于深度强化学习的模型训练方法;选取雄安新区对外主干路网中荣乌高速公路某合流区瓶颈作为实验场景,利用深度强化学习算法对模型进行训练,并将训练过程中控制策略的表现与经典匝道控制方法比较,从而对学习成本进行量化分析;选取不同仿真模型及多组模型参数作为测试环境,分析训练环境与测试环境差异对控制策略的影响。结果表明:当训练环境与测试环境差异程度在20%以内时,强化学习控制方法在提升通行效率方面显著优于经典匝道控制方法;而当差异程度超过20%时,两种方法效果差异不明显。
中图分类号:
韩雨, 陈志轩, 王翊萱, 李春杰, 雷伟, 焦彦利, 刘攀. 基于深度强化学习的入口匝道流量调控方法[J]. 汽车安全与节能学报, 2025, 16(4): 587-597.
HAN Yu, CHEN Zhixuan, WANG Yixuan, LI Chunjie, LEI Wei, JIAO Yanli, LIU Pan. Deep reinforcement learning-based strategy for freeway ramp metering[J]. Journal of Automotive Safety and Energy, 2025, 16(4): 587-597.
| 算法: 基于TD3的匝道控制模型训练算法 |
|---|
| 算法输入: 可供交互的仿真环境 算法输出: 匝道控制策略 1 设定算法参数,包括:最大训练回合数max_episode、每回合步数J、奖励衰减因子γ、记忆容量memory_size、抽样条数batch_size、探索噪声σexpl、策略噪声σpol、策略噪声界限c、软更新参数τ等; 2 随机初始化Actor网络π?和Critic网络Qθ1 、Qθ2的网络参数?、θ1、θ2,并将网络参数复制给相对应的目标网络的参数值?'、θ'1、θ'2; 3 for i = 1,2,…,max_episode do 4 初始化经验池及探索噪声σexpl 5 初始化仿真环境 6 for j = 1,2…,J do 7 智能体根据当前观测到的状态生成动作 8 智能体与环境交互 9 将本次交互得到的数据样本存入经验池中 10 从经验池中随机抽取训练样本 11 向训练样本的动作向量a加入策略噪声, a = a + clip(randnorm (0, σpolicy), -c, c) 12 基于式(7)最小化损失函数更新Critic主网络参数 13 基于式(8)计算策略梯度更新Actor主网络参数 14 更新目标网络参数,?' = τ? + (1- τ)?', θ'i = τθ + (1- τ) θ' 15 end for 16 end for |
| 算法: 基于TD3的匝道控制模型训练算法 |
|---|
| 算法输入: 可供交互的仿真环境 算法输出: 匝道控制策略 1 设定算法参数,包括:最大训练回合数max_episode、每回合步数J、奖励衰减因子γ、记忆容量memory_size、抽样条数batch_size、探索噪声σexpl、策略噪声σpol、策略噪声界限c、软更新参数τ等; 2 随机初始化Actor网络π?和Critic网络Qθ1 、Qθ2的网络参数?、θ1、θ2,并将网络参数复制给相对应的目标网络的参数值?'、θ'1、θ'2; 3 for i = 1,2,…,max_episode do 4 初始化经验池及探索噪声σexpl 5 初始化仿真环境 6 for j = 1,2…,J do 7 智能体根据当前观测到的状态生成动作 8 智能体与环境交互 9 将本次交互得到的数据样本存入经验池中 10 从经验池中随机抽取训练样本 11 向训练样本的动作向量a加入策略噪声, a = a + clip(randnorm (0, σpolicy), -c, c) 12 基于式(7)最小化损失函数更新Critic主网络参数 13 基于式(8)计算策略梯度更新Actor主网络参数 14 更新目标网络参数,?' = τ? + (1- τ)?', θ'i = τθ + (1- τ) θ' 15 end for 16 end for |
| 模型参数 | 取值 | 参数含义 |
|---|---|---|
| Dmin / m | 2.5 | 车辆静止时与前车保持的最小间距 |
| amax / (m·s-2) | 2.6 | 车辆最大加速度 |
| |bmax| / (m·s-2) | 4.5 | 车辆最大减速度 |
| h / s | 1.1 | 期望跟驰车头时距 |
| σ | 0.4 | 驾驶失误概率 |
| lcAssertive | 1.0 | 较小的可换道间距的接受程度 |
| lcStrategic | 1.0 | 换道的迫切性 |
| lcCooperative | 1.0 | 换道时与周围车辆的合作性 |
| Nep_max | 400 | 智能体训练的最大回合数 |
| γ | 0.99 | 累计奖励衰减因子 |
| Nmemory_max | 2 048 | 记忆容量 |
| batch size | 256 | 每次学习的抽样数 |
| σexpl | 0.4 | 探索噪声 |
| σpol | 0.3 | 策略噪声 |
| c | 0.5 | 策略噪声界限 |
| τ | 0.02 | 软更新参数 |
| 模型参数 | 取值 | 参数含义 |
|---|---|---|
| Dmin / m | 2.5 | 车辆静止时与前车保持的最小间距 |
| amax / (m·s-2) | 2.6 | 车辆最大加速度 |
| |bmax| / (m·s-2) | 4.5 | 车辆最大减速度 |
| h / s | 1.1 | 期望跟驰车头时距 |
| σ | 0.4 | 驾驶失误概率 |
| lcAssertive | 1.0 | 较小的可换道间距的接受程度 |
| lcStrategic | 1.0 | 换道的迫切性 |
| lcCooperative | 1.0 | 换道时与周围车辆的合作性 |
| Nep_max | 400 | 智能体训练的最大回合数 |
| γ | 0.99 | 累计奖励衰减因子 |
| Nmemory_max | 2 048 | 记忆容量 |
| batch size | 256 | 每次学习的抽样数 |
| σexpl | 0.4 | 探索噪声 |
| σpol | 0.3 | 策略噪声 |
| c | 0.5 | 策略噪声界限 |
| τ | 0.02 | 软更新参数 |
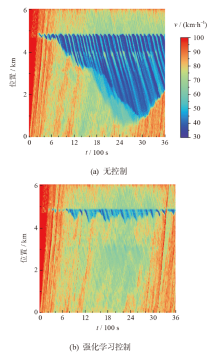
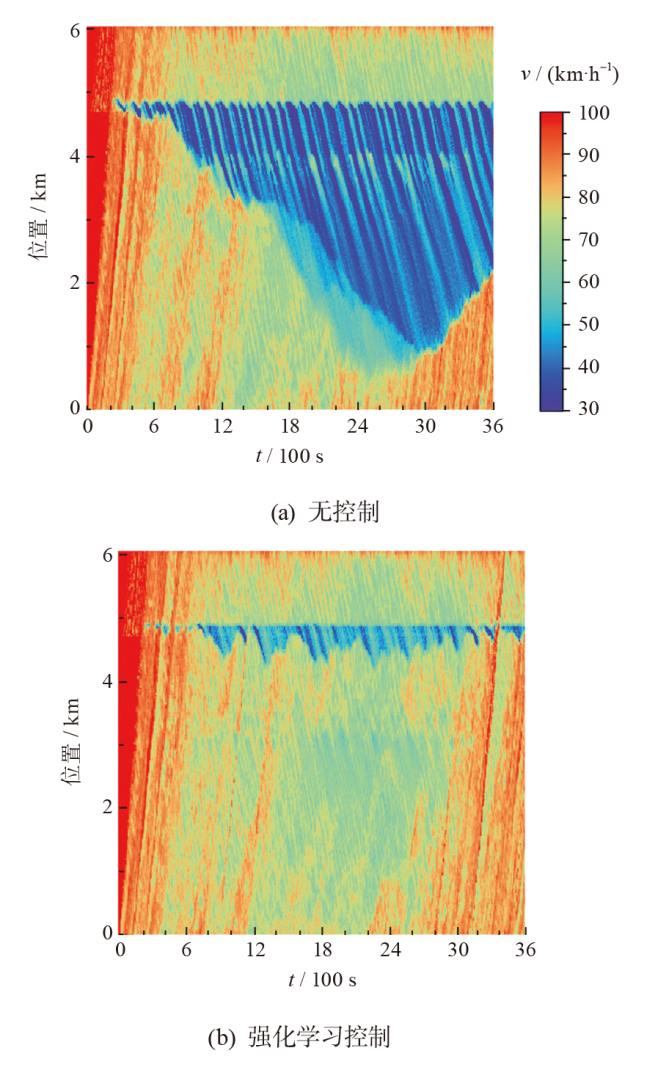
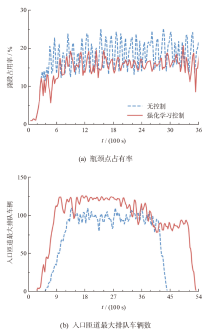
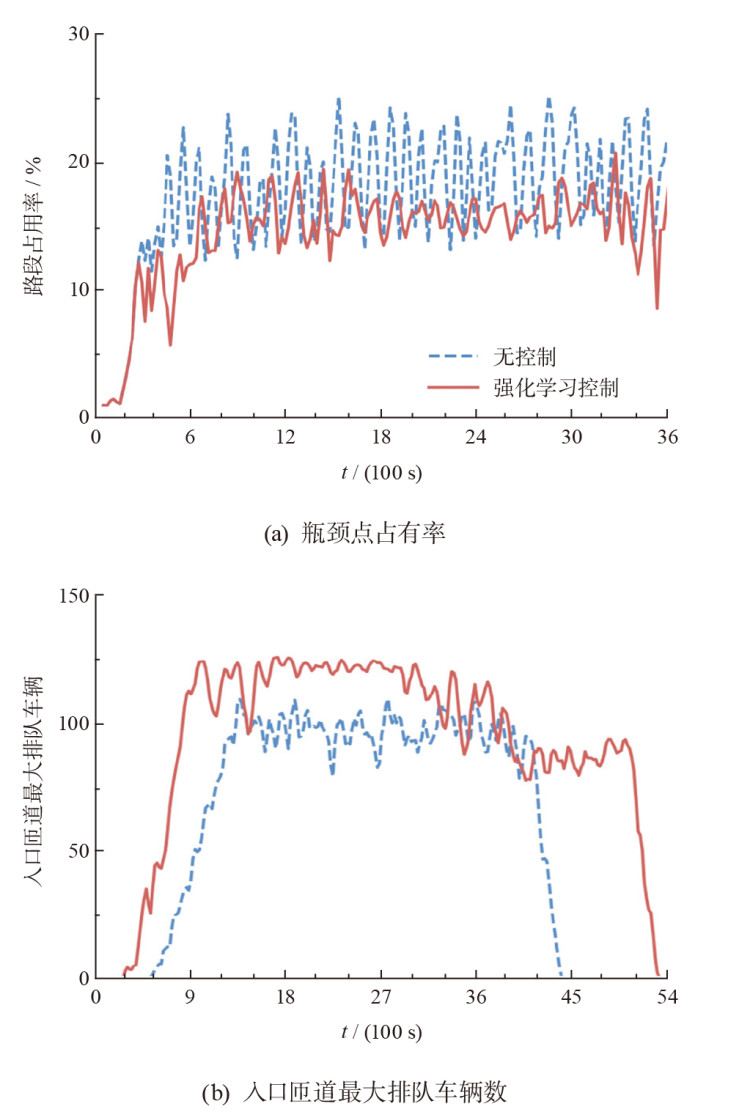
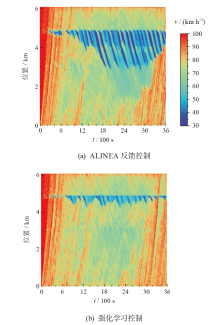
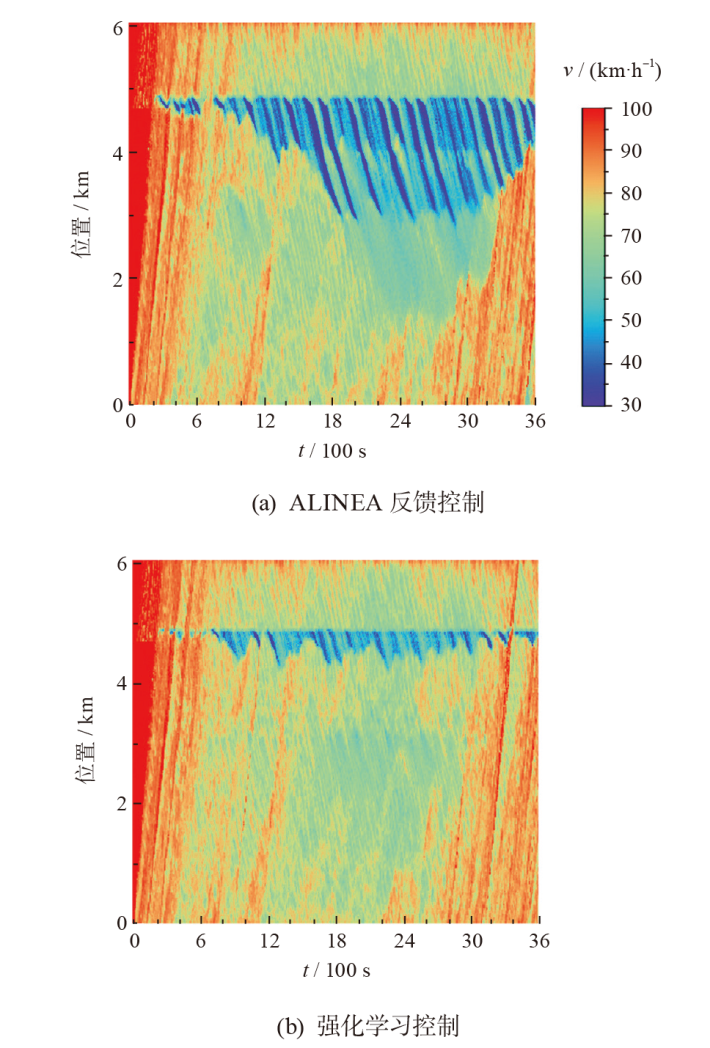
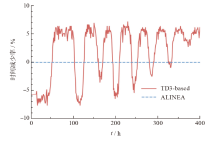
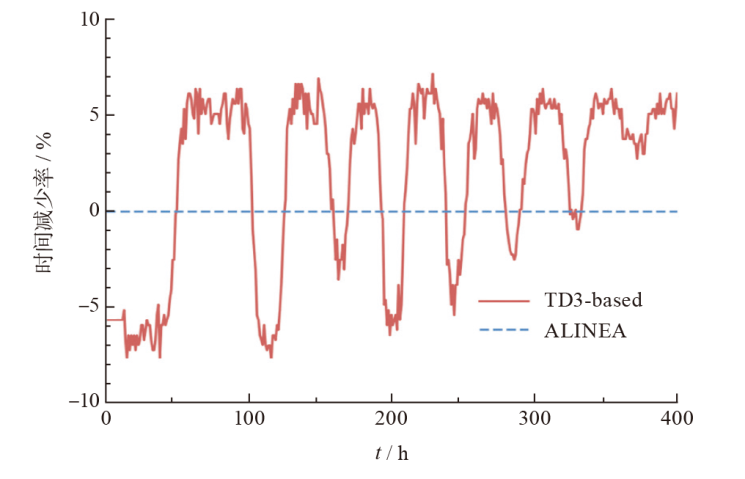
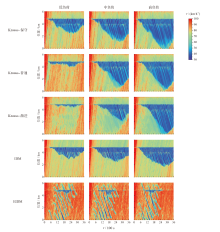

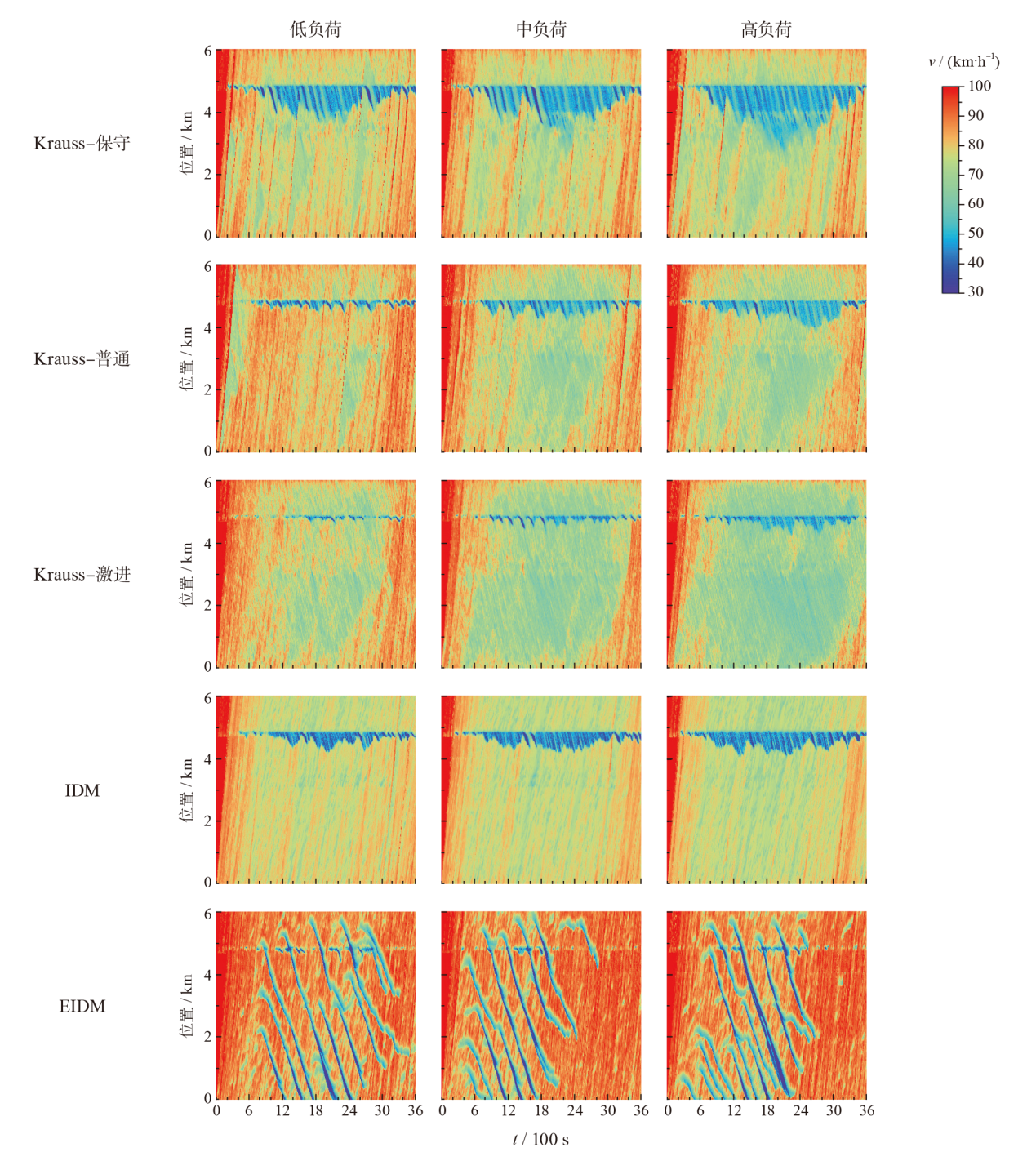
| 微观动力学模型 | 低负荷 | 中负荷 | 高负荷 |
|---|---|---|---|
| Krauss-保守 | 21.13 | 17.81 | 16.95 |
| Krauss-普通 | 24.86 | 0.00 | 16.03 |
| Krauss-激进 | 21.98 | 17.12 | 15.61 |
| IDM | 17.49 | 15.24 | 13.19 |
| EIDM | 28.25 | 26.28 | 22.08 |
| 微观动力学模型 | 低负荷 | 中负荷 | 高负荷 |
|---|---|---|---|
| Krauss-保守 | 21.13 | 17.81 | 16.95 |
| Krauss-普通 | 24.86 | 0.00 | 16.03 |
| Krauss-激进 | 21.98 | 17.12 | 15.61 |
| IDM | 17.49 | 15.24 | 13.19 |
| EIDM | 28.25 | 26.28 | 22.08 |
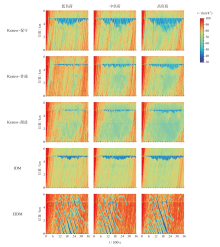
| 微观动力学模型 | 低负荷 | 中负荷 | 高负荷 | |||||
|---|---|---|---|---|---|---|---|---|
| 强化学习 | ALINEA | 强化学习 | ALINEA | 强化学习 | ALINEA | |||
| Krauss-保守 | 13.72 | 16.24 | 30.80 | 28.19 | 35.89 | 28.92 | ||
| Krauss-普通 | 0.28 | 0.11 | 35.51 | 20.10 | 33.70 | 16.09 | ||
| Krauss-激进 | 5.07 | 3.17 | 19.43 | 19.26 | 26.92 | 11.14 | ||
| IDM | 11.61 | 1.93 | 24.50 | 9.26 | 30.21 | 11.84 | ||
| EIDM | -10.89 | -6.65 | 5.89 | 18.11 | 3.24 | 4.55 | ||
| 微观动力学模型 | 低负荷 | 中负荷 | 高负荷 | |||||
|---|---|---|---|---|---|---|---|---|
| 强化学习 | ALINEA | 强化学习 | ALINEA | 强化学习 | ALINEA | |||
| Krauss-保守 | 13.72 | 16.24 | 30.80 | 28.19 | 35.89 | 28.92 | ||
| Krauss-普通 | 0.28 | 0.11 | 35.51 | 20.10 | 33.70 | 16.09 | ||
| Krauss-激进 | 5.07 | 3.17 | 19.43 | 19.26 | 26.92 | 11.14 | ||
| IDM | 11.61 | 1.93 | 24.50 | 9.26 | 30.21 | 11.84 | ||
| EIDM | -10.89 | -6.65 | 5.89 | 18.11 | 3.24 | 4.55 | ||
| [1] | Papageorgiou M, Kotsialos A. Freeway ramp metering: An overview[J]. IEEE Trans Intel Transport Syst, 2002, 3(4): 271-281. |
| [2] | WANG Jin, May A D. Computer model for optimal freeway on-ramp control[J]. Highw Res Record, 1973, 469: 16-25. |
| [3] | Papageorgiou M, Hadj-Salem H, Blosseville J M. ALINEA: A local feedback control law for on-ramp metering[J]. Transport Res Record, 1991, 1320(1): 58-67. |
| [4] | WANG Yibing, Kosmatopoulos E B, Papageorgiou M, et al. Local ramp metering in the presence of a distant downstream bottleneck: Theoretical analysis and simulation study[J]. IEEE Trans Intel Transport Syst, 2014, 15(5): 2024-2039. |
| [5] | Papageorgiou M, Hadj-Salem H, Middelham F. ALINEA local ramp metering: Summary of field results[J]. Transport Res Record, 1997, 1603(1): 90-98. |
| [6] | Papamichail I, Papageorgiou M, Vong V, et al. Heuristic ramp-metering coordination strategy implemented at Monash freeway, Australia[J]. Transport Res Record, 2010, 2178(1): 10-20. |
| [7] | Hegyi A, De Schutter B, Hellendoorn H. Model predictive control for optimal coordination of ramp metering and variable speed limits[J]. Transport Res Part C: Emerg Tech, 2005, 13(3): 185-209. |
| [8] | Bellemans T, De Schutter B, De Moor B. Model predictive control for ramp metering of motorway traffic: A case study[J]. Contr Engi Pract, 2006, 14(7): 757-767. |
| [9] | LI Zhibin, LIU Pan, Xu Chengcheng, et al. Reinforcement learning-based variable speed limit control strategy to reduce traffic congestion at freeway recurrent bottlenecks[J]. IEEE Trans Intel Transport Syst, 2017, 18(11): 3204-3217. |
| [10] |
韩雨, 郭延永, 张乐, 等. 消除高速公路运动波的可变限速控制方法[J]. 中国公路学报, 2022, 35(1): 151-158.
doi: 10.19721/j.cnki.1001-7372.2022.01.013 |
| HAN Yu, GUO Yanyong, ZHANG Le, et al. An optimal variable speed limit control approach against freeway jam waves[J]. China J Highw Transport, 2022, 35(1): 151-158. (in Chinese) | |
| [11] | 涂辉招, 孙立军, 高子翔. 基于风险评估技术的城市快速路多匝道协调控制时机研究[J]. 中国公路学报, 2015, 28(7): 86-92,101. |
| TU Huizhao, SUN Lijun, GAO Zixiang. Study on control timing of coordinated multi-ramp for urban freeway corridors based on risk assessment technique[J]. China J Highw Transport, 2015, 28(7): 86-92, 101. (in Chinese) | |
| [12] | Noaeen M, Naik A, Goodman L, et al. Reinforcement learning in urban network traffic signal control: A systematic literature review[J]. Expert Syst Appl, 2022, 199: No 116830. |
| [13] | Mannion P, Duggan J, Howley E. An experimental review of reinforcement learning algorithms for adaptive traffic signal[M]// Auto Road Transport Support Syst, Springer International Publishing, AG Gewerbestraße 11, 6330 Cham, Switzerland 2016: 47-66. |
| [14] | 徐东伟, 周磊, 王达, 等. 基于深度强化学习的城市交通信号控制综述[J]. 交通运输工程与信息学报, 2022, 20(1): 15-30. |
| XU Dongwei, ZHOU Lei, WANG Da, et al. A review of urban traffic signal control based on deep reinforcement learning[J]. J Transport Engi Info, 2022, 20(1): 15-30. (in Chinese) | |
| [15] | HAN Yu, WANG Meng, LI Linghui, et al. A physics-informed reinforcement learning-based strategy for local and coordinated ramp metering[J]. Transport Res Part C: Emerg Tech, 2022, 137: No 103584. |
| [16] | HAN Yu, Hegyi A, ZHANG Le, et al. A new reinforcement learning-based variable speed limit control approach to improve traffic efficiency against freeway jam waves[J]. Transport Res Part C: Emerg Tech, 2022, 144: No 103900. |
| [17] | Christopher J C, Watkins H. Technical note Q-learning[J]. Mach Learn. 1992(8): 279-292. |
| [18] | Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518: 529-533. |
| [19] | Gullapalli V, A stochastic reinforcement learning algorithm for learning real-valued functions[J]. Neural Netw, 1990, 3(6): 671-692. |
| [20] | Timothy P L, Jonathan H, Pritzel A, et al. Continuous control with deep reinforcement learning[C]. arXiv:1509.02971. 2015. |
| [21] | Fujimoto S, van Hoof H, Meger D. Addressing function approximation error in Actor-Critic methods[C]. arXiv:1802.09477. 2018. |
| [22] | Spiliopoulou A D, Manolis D, Papamichail I, et al. Queue management techniques for metered freeway on-ramps[J]. Transport Res Record. 2010, 2178(1): 40-48. |
| [23] | LIU Yang, WU Fanyou, LIU Zhiyuan, et al. Can language models be used for real-world urban-delivery route optimization?[J]. Innovation, 2023, 4(6): No 100520. |
| [24] | 何逸煦, 林泓熠, 刘洋, 等. 强化学习在自动驾驶技术中的应用与挑战[J]. 同济大学学报(自然科学版), 2024, 52(4): 520-531. |
| HE Yixu, LIN Hongyi, LIU Yang, et al. Applications and challenges of reinforcement learning in autonomous driving technology[J]. J Tongji Univ (Nat Sci Edit), 2024, 52(4): 520-531. (in Chinese) | |
| [25] | 柳鹏, 赵克刚, 梁志豪, 等. 基于深度强化学习CLPER-DDPG的车辆纵向速度规划[J]. 汽车安全与节能学报, 2024(5): 702-710. |
| LIU Peng, ZHAO Kegang, LIANG Zhihao, et al. Longitudinal velocity planning for vehicles based on CLPER-DDPG deep reinforcement learning[J]. J Autom Safe Energ, 2024, 15(5): 702-710. (in Chinese) | |
| [26] | 李文礼, 邱凡珂, 廖达明, 等. 基于深度强化学习的高速公路换道跟踪控制模型[J]. 汽车安全与节能学报, 2022, 13(4): 750-759. |
| LI Wenli, QIU Fanke, LIAO Daming, et al. Lane-changing and tracking control model for expressways based on deep reinforcement learning[J]. J Autom Safe Energ, 2022, 13(4): 750-759. (in Chinese) | |
| [27] | 刘洋, 占佳豪, 李深, 等. 自动驾驶技术的未来: 单车智能和智能车路协同[J]. 汽车安全与节能学报, 2024, 15(5): 611-633. |
| LIU Yang, ZHAN Jiahao, LI Shen, et al. The future of autonomous driving technology: single-vehicle intelligence and intelligent vehicle-road coordination[J]. J Autom Safe Energ, 2024, 15(5): 611-633. (in Chinese) | |
| [28] |
林泓熠, 刘洋, 李深, 等. 车路协同系统关键技术研究进展[J]. 华南理工大学学报(自然科学版), 2023, 51(10): 46-67.
doi: 10.12141/j.issn.1000-565X.230200 |
| LIN Hongyi, LIU Yang, LI Shen, et al. Research progress on key technologies of cooperative vehicle - infrastructure system[J]. J South China Univ Tech (Nat Sci Edit), 2023, 51(10): 46-67. (in Chinese) | |
| [29] | 李颖, 费怡瑄, 安毅生, 等. 智能交通场景下的地图匹配技术综述[J]. 交通运输工程学报, 2024, 24(5): 301-332. |
| LI Ying, FEI Yixuan, AN Yisheng, et al. A Review of map matching technology in intelligent transportation scenarios[J]. J Traf Transport Engi, 2024, 24(5): 301-332. (in Chinese) | |
| [30] | HAN Yu, WU Jiarui, DING Fan, et al. Capacity drop at active bottlenecks: An empirical study based on trajectory data[J]. Transport Res Part B: Methodol, 2025, 196: No 103218. |
| [1] | 王越, 段宏伟, 钟薇, 杨路, 何雷, 柴福来, 石晓杨. 融合GoT-SAC的领航—跟随式多车编队路径规划方法[J]. 汽车安全与节能学报, 2026, 17(1): 122-129. |
| [2] | 黎子源, 刘强, 李鼎立, 李子龙. 基于深度强化学习的智能网联车辆盲区通行策略[J]. 汽车安全与节能学报, 2025, 16(3): 470-477. |
| [3] | 胡志龙, 裴晓飞, 周洪龙, 魏炜冉. 基于风险敏感的自动驾驶汽车分层强化学习决策[J]. 汽车安全与节能学报, 2025, 16(2): 326-333. |
| [4] | 张富椿, 尹燕莉, 马永娟, 肖杭洋, 陈海鑫, 余凯. 网联混合动力汽车队列的生态驾驶与能量管理分层控制[J]. 汽车安全与节能学报, 2025, 16(1): 159-169. |
| [5] | 蔡田茂, 孔伟伟, 罗禹贡, 石佳, 姬鹏霄, 李聪民. 基于MADDPG算法的匝道合流区多车协同控制[J]. 汽车安全与节能学报, 2024, 15(6): 923-933. |
| [6] | 张新锋, 吴琳. 基于集成深度强化学习的自动驾驶车辆行为决策模型[J]. 汽车安全与节能学报, 2023, 14(4): 472-479. |
| [7] | 韩玲, 张晖, 方若愚, 刘国鹏, 朱长盛, 迟瑞丰. 基于改进深度强化学习的全局路径规划策略[J]. 汽车安全与节能学报, 2023, 14(2): 202-211. |
| [8] | 冯耀, 景首才, 惠飞, 赵祥模, 刘建蓓. 基于深度强化学习的智能网联车辆换道轨迹规划方法[J]. 汽车安全与节能学报, 2022, 13(4): 705-717. |
| [9] | 李文礼, 邱凡珂, 廖达明, 任勇鹏, 易帆. 基于深度强化学习的高速公路换道跟踪控制模型[J]. 汽车安全与节能学报, 2022, 13(4): 750-759. |
| [10] | 郑阳俊, 贺帅, 帅志斌, 李建秋, 盖江涛, 李勇, 张颖, 李国辉. 基于DRL的四轮独立驱动电动车辆的侧向车速估计[J]. 汽车安全与节能学报, 2022, 13(2): 309-316. |
| [11] | 徐杰, 裴晓飞, 杨波, 方志刚. 融合车辆轨迹预测的学习型自动驾驶决策[J]. 汽车安全与节能学报, 2022, 13(2): 317-324. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||