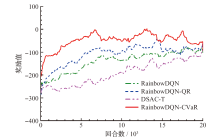
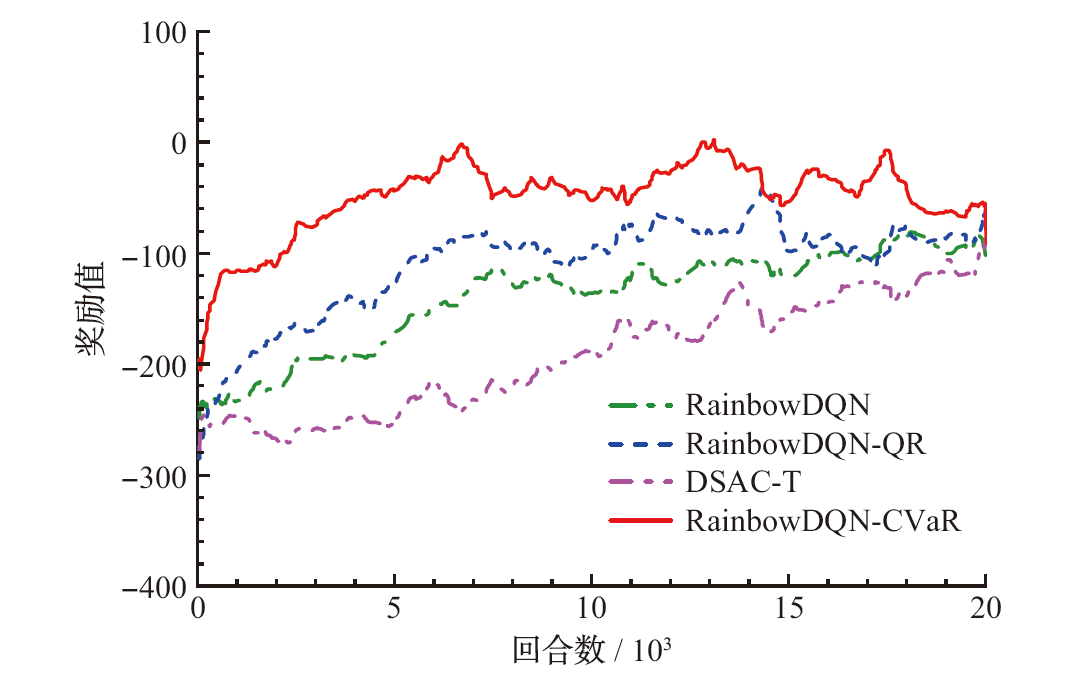
| [1] |
Bojarski M, Testa D, Dworakowski D, et al. End to end learning for self-driving car[J/OL]. (2016-04-25) https://doi.org/10.48550/arXiv.1604.07316.
|
| [2] |
杨顺. 从虚拟到现实的智能车辆深度强化学习控制研究[D]. 长春: 吉林大学, 2019.
|
|
YANG Shun. Research on deep reinforcement learning control of intelligent vehicles from virtual to real[D]. Changchun: Jilin University, 2019. (in Chinese)
|
| [3] |
李伟东, 马草原, 史浩, 等. 基于分层强化学习的自动驾驶决策控制算法[J/OL]. 吉林大学学报(工学版), 2023: 1-8. (2023-12-19) https://doi.org/10.13229/j.cnki.jdxbgxb.20230891.
|
|
LI Weidong, MA Caoyuan, SHI Hao, et al. Autonomous driving decision-making control algorithm based on hierarchical reinforcement learning[J/OL]. J Jilin University (Engi Tech Edit), 2023: 1-8. (2023-12-19) https://doi.org/10.13229/j.cnki.jdxbgxb.20230891. (in Chinese)
|
| [4] |
YANG Lan, HU Zhiqiang, WANG Liang, et al. Entire route eco-driving method for electric bus based on rule-based reinforcement learning[J]. Transport Res, Part E: Logist Transport Rev, 2024, 189: 1-24.
|
| [5] |
Min K, Kim H, Huh K. Deep distributional reinforcement learning based high-Level driving policy determination[J]. IEEE Transport Intel Vehi, 2019, 4(3): 416-424.
|
| [6] |
ZHOU Lun, WANG Ke, YU Huang, et al. Path planning of improved DQN based on quantile regression [C]// 2022 Int’l Conf Artif Intel Comput Info Tech (AICIT). IEEE, 2022: 1-4.
|
| [7] |
MA Xiaoteng, XIA Li, ZHOU Zhengyuan, et al. DSAC: Distributional soft actor critic for risk-sensitive reinforcement learning[J/OL]. (2020-04-30) https://doi.org/10.48550/arXiv.2004.14547.
|
| [8] |
Ugur Y, Tufan K, Kemal U. A new approach for tactical decision making in lane changing:Sample efficient deep Q learning with a safety feedback reward [C]// 2020 IEEE Intel Vehi Symp (IV). Las Vegas, NV, USA, 2020: 1156-1161.
|
| [9] |
Bouton M, Nakhaei A, Fujimura K, et al. Safe reinforcement learning with scene decomposition for navigating complex urban environments [C]// 2019 IEEE Intel Vehi Symp (IV). Paris, France, 2019: 1469-1476.
|
| [10] |
CHEN Dong, JIANG Longsheng, WANG Yue, et al. Autonomous driving using safe reinforcement learning by incorporating a regret-based human lane-changing decision model [C]// 2020 Ame Contr Conf (ACC). Denver, CO, USA, 2020: 4355-4361.
|
| [11] |
Baheri A, Nageshrao S, Tseng H, et al. Deep reinforcement learning with enhanced safety for autonomous highway driving [C]// 2020 IEEE Intel Vehi Symp (IV). Las Vegas, NV, USA, 2020: 1550-1555.
|
| [12] |
Bellemare M G, Dabney W, Munos R. A distributional perspective on reinforcement learning[C]// Int’l Conf Mach Learn. PMLR, 2017: 449-458.
|
| [13] |
Danial K, Carlos L, Martin L, et al. Risk-aware high-level decisions for automated driving at occluded intersections with reinforcement learning [C]// 2020 IEEE Intel Vehi Symp (IV). Las Vegas, NV, USA, 2020: 1205-1212.
|
| [14] |
WEN Lu, DUAN Jingliang, LI Shengbo, et al. Safe reinforcement learning for autonomous vehicles through parallel constrained policy optimization [C]// 2020 IEEE 23rd Int’l Conf Intel Transport Syst (ITSC). Rhodes, Greece, 2020: 1-7.
|
| [15] |
詹吟霄, 刘潇, 梁军. 基于深度强化学习与风险矫正的智能车辆决策研究[J]. 汽车工程学报, 2023, 13(5): 656-667.
|
|
ZHAN Yinxiao, LIU Xiao, LIANG Jun. Research on intelligent vehicle decision-making based on deep reinforcement learning and risk correction[J]. China J Autom Engi, 2023, 13(5): 656-667. (in Chinese)
|
| [16] |
Dabney W, Rowland M, Bellemare M, et al. Distributional reinforcement learning with quantile regression[C]// Proc AAAI Conf Artif Intel. New Orleans, USA, 2018: 2892-2901.
|
| [17] |
DUAN Jingliang, WANG Wenxuan, XIAO Liming, et al. DSAC-T: Distributional soft actor-critic with three refinements[J/OL]. (2023-10-09) https://doi.org/10.48550/arXiv.2310.05858.
|
 ), 裴晓飞1,2,*(
), 裴晓飞1,2,*(