欢迎访问《汽车安全与节能学报》,
汽车安全与节能学报 ›› 2024, Vol. 15 ›› Issue (4): 591-601.DOI: 10.3969/j.issn.1674-8484.2024.04.016
张晨1( ), 刘畅1, 赵津1, 王广玮1,2,*(), 许庆2
), 刘畅1, 赵津1, 王广玮1,2,*(), 许庆2
收稿日期:2023-12-14
修回日期:2024-03-18
出版日期:2024-08-31
发布日期:2024-09-05
通讯作者:
*王广玮,副教授。E-mail:作者简介:张晨(1998—),男(汉),山东,硕士研究生。E-mail:gschenzhang21@gzu.edu.cn。
基金资助:
ZHANG Chen1(), LIU Chang1, ZHAO Jin1, WANG Guangwei1,2,*(), XU Qing2
Received:2023-12-14
Revised:2024-03-18
Online:2024-08-31
Published:2024-09-05
摘要:
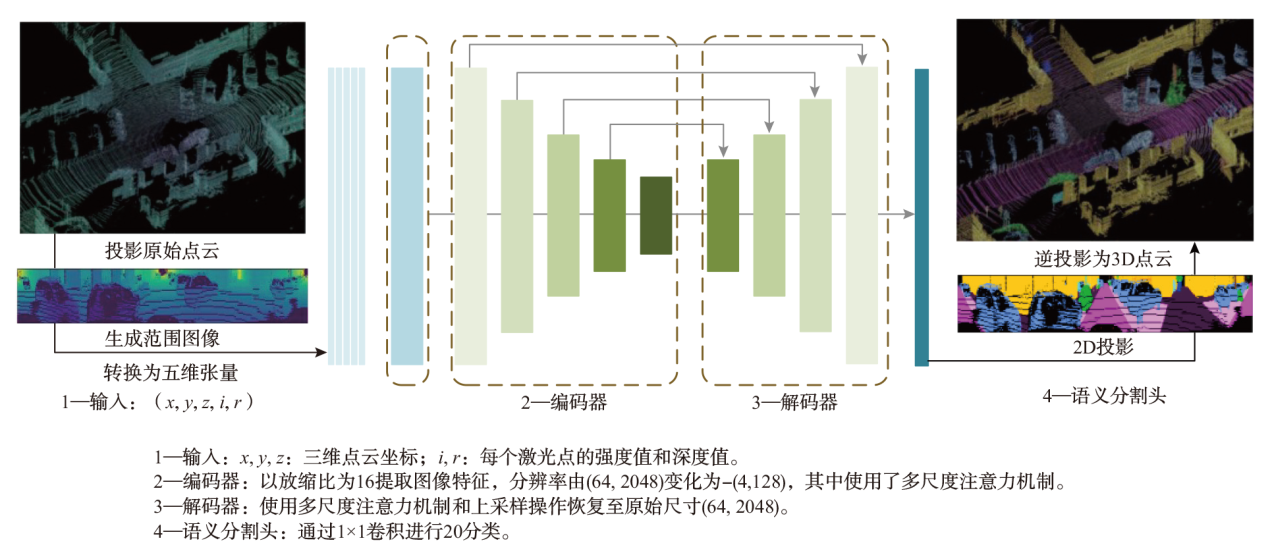
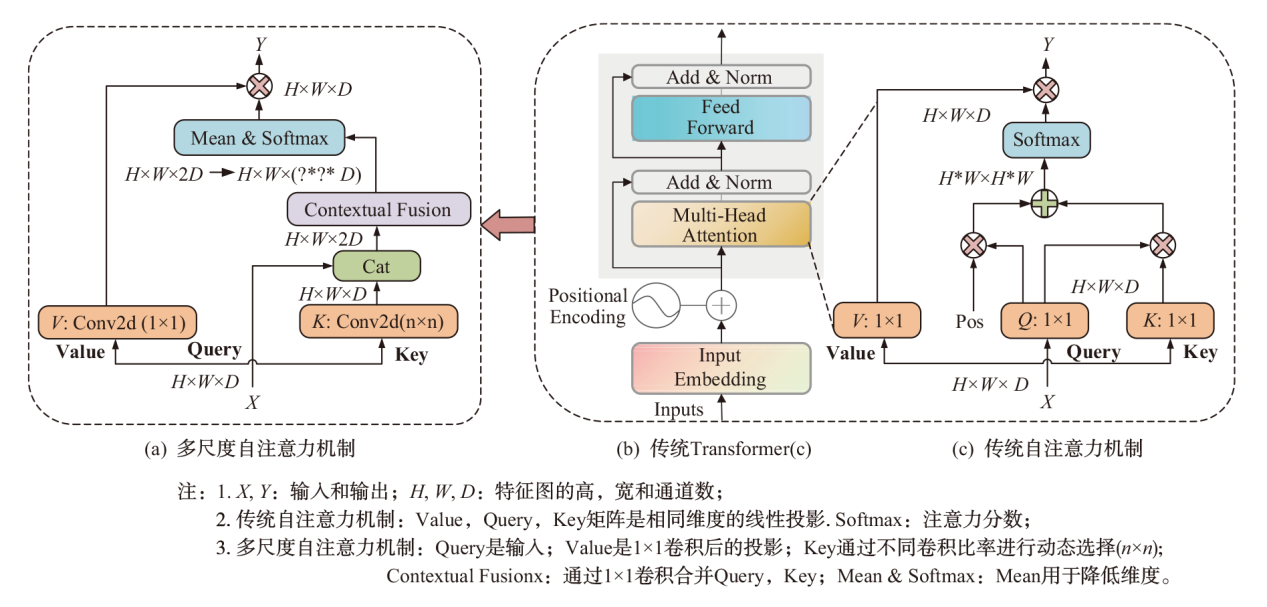
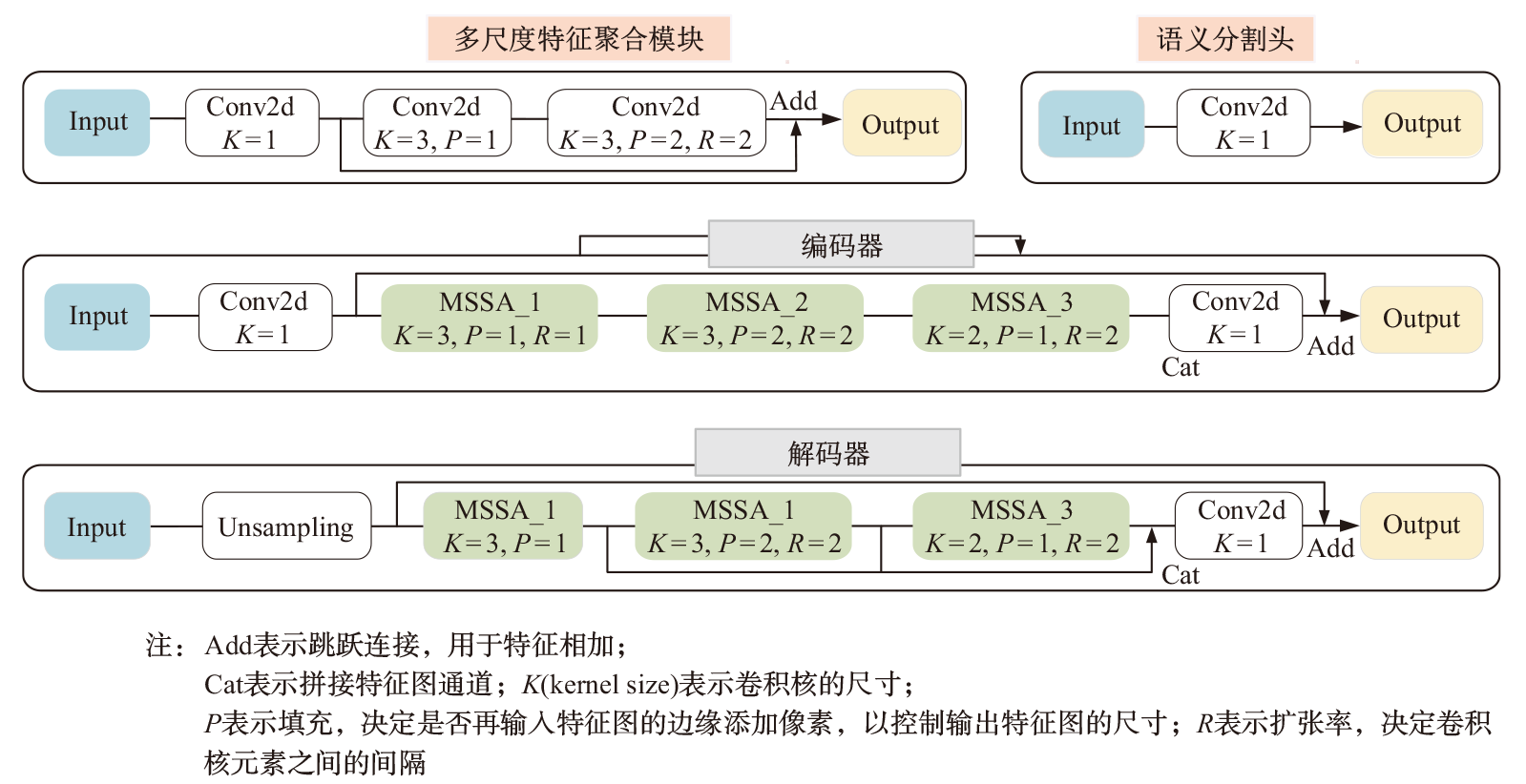
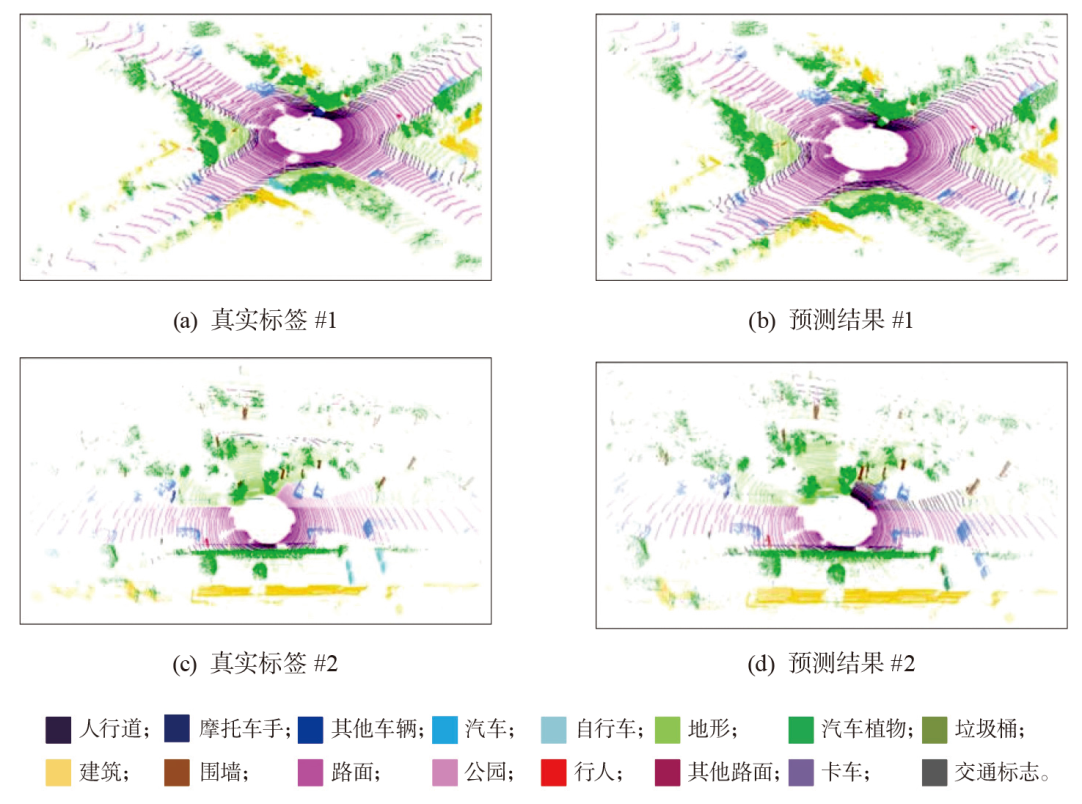
为既能提高分割精度,又能克服车载计算资源局限,提出一种面向移动机器人平台的车载实时点云语义分割方法,并进行了综合实验。该方法采用基于投影的激光雷达语义分割方法,将三维点云投影到球面图像,并结合二维卷积进行分割。引入多头注意力机制(MHSA),实现轻量级语义分割模型,以一种全新的方式,将一种深度学习模型架构Transformer映射到卷积。将Transformer的MHSA迁移至卷积,以形成多尺度自注意力机制(MSSA)。结果表明:与当前主流方法CENet、FIDNet 、PolarNet相比,本方法在NVIDIA JETSON AGX Xavier计算平台上保持了较高的分割精度(平均交并比为63.9%)及较高的检测速率(41 帧/s),从而证明了其对移动机器人平台的适用性。
中图分类号:
张晨, 刘畅, 赵津, 王广玮, 许庆. 基于多尺度注意力机制的实时激光雷达点云语义的分割[J]. 汽车安全与节能学报, 2024, 15(4): 591-601.
ZHANG Chen, LIU Chang, ZHAO Jin, WANG Guangwei, XU Qing. Semantic segmentation of real-time LiDAR point clouds based on multi-scale self-attention[J]. Journal of Automotive Safety and Energy, 2024, 15(4): 591-601.

| 类型 | 方法 | mIoU / % | 参数数量/ 106 | IoU / % | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 车 | 自行车 | 摩托车 | 卡车 | 其他 车辆 | 人 | 自行 车手 | 摩托 车手 | 路面 | 停车牌 | 人行道 | 其他 路面 | ||||
| 点 | Pointnet | 14.6 | 3.0 | 46.3 | 1.3 | 0.3 | 0.1 | 0.8 | 0.2 | 0.2 | 0.0 | 61.6 | 15.8 | 35.7 | 1.4 |
| Pointnet+ | 20.1 | 6.0 | 53.7 | 1.9 | 0.2 | 0.9 | 0.2 | 0.9 | 1.0 | 0.0 | 72.0 | 18.7 | 41.8 | 5.6 | |
| SPGraph | 20.0 | 0.3 | 68.3 | 0.9 | 4.5 | 0.9 | 0.8 | 1.0 | 6.0 | 0.0 | 49.5 | 1.7 | 24.2 | 0.3 | |
| SPLATNet | 22.8 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 70.4 | 0.8 | 41.5 | 0.0 | |
| TangentConv | 35.9 | 0.4 | 86.8 | 1.3 | 12.7 | 11.6 | 10.2 | 17.1 | 20.2 | 0.5 | 82.9 | 15.2 | 61.7 | 9.0 | |
| P2Net | 39.8 | 6.0 | 85.6 | 20.4 | 14.4 | 14.4 | 11.5 | 16.9 | 24.9 | 5.9 | 87.8 | 47.5 | 67.3 | 7.3 | |
| RandLA-Net | 53.9 | 2.1 | 94.2 | 26.0 | 25.8 | 40.1 | 38.9 | 49.2 | 48.2 | 7.2 | 90.7 | 60.3 | 73.7 | 20.4 | |
| PolarNet | 54.3 | 16.6 | 93.8 | 40.3 | 30.1 | 22.9 | 28.5 | 43.2 | 40.2 | 5.6 | 90.8 | 61.7 | 74.4 | 21.7 | |
| 体素 | Cylinder3D | 67.8 | - | 97.1 | 67.6 | 64.0 | 59.0 | 58.6 | 73.9 | 67.9 | 36.0 | 91.4 | 65.1 | 75.5 | 32.3 |
| MinkowskiNet | 63.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| SPVCNN | 63.8 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| SPVCNN-lite | 58.5 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| 投影 | Squeezeseg | 29.5 | 1.0 | 68.8 | 16.0 | 4.1 | 3.3 | 3.6 | 12.9 | 13.1 | 0.9 | 85.4 | 26.9 | 54.3 | 4.5 |
| SqueezesegV2 | 39.6 | 1.0 | 82.7 | 21.0 | 22.6 | 14.5 | 15.9 | 20.2 | 24.3 | 2.9 | 88.5 | 42.4 | 65.5 | 18.7 | |
| SqueezesegV3 | 55.9 | - | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | |
| RangeNet21 | 47.4 | 25.0 | 85.4 | 26.2 | 26.5 | 18.6 | 15.6 | 31.8 | 33.6 | 4.0 | 91.4 | 57.0 | 74.0 | 26.4 | |
| RangeNet53 | 52.2 | 50.0 | 91.4 | 25.7 | 34.4 | 25.7 | 23.0 | 38.3 | 38.8 | 4.8 | 91.8 | 65.0 | 75.2 | 27.8 | |
| MINet + k-NN | 55.2 | 2.0 | 90.1 | 41.8 | 34.0 | 29.9 | 23.6 | 51.4 | 52.4 | 25.0 | 90.5 | 59.0 | 72.6 | 25.8 | |
| Lite-HDSeg | 63.8 | - | 92.3 | 40.0 | 55.4 | 37.7 | 39.6 | 59.2 | 71.6 | 54.3 | 93.0 | 68.2 | 78.3 | 29.3 | |
| 3D-MiniNet | 55.8 | - | 90.5 | 42.3 | 42.1 | 28.5 | 29.4 | 47.8 | 44.1 | 14.5 | 91.6 | 64.2 | 74.5 | 25.4 | |
| SalsaNext | 59.5 | 6.7 | 91.9 | 48.3 | 38.6 | 38.9 | 31.9 | 60.2 | 59.0 | 19.4 | 91.7 | 63.7 | 75.8 | 29.1 | |
| FIDNet | 58.6 | 6.3 | 93.0 | 45.7 | 42.0 | 27.9 | 32.6 | 62.6 | 58.1 | 30.5 | 90.8 | 58.3 | 74.9 | 20.1 | |
| CE-Net | 64.7 | 6.9 | 91.9 | 58.6 | 50.3 | 40.6 | 42.3 | 68.9 | 65.9 | 43.5 | 90.3 | 60.9 | 75.1 | 31.5 | |
| 本文方法 | 63.9 | 5.8 | 95.3 | 46.3 | 57.0 | 79.6 | 43.1 | 68.5 | 80.5 | 0.0 | 94.8 | 48.4 | 81.8 | 0.3 | |
| 类型 | 方法 | mIoU / % | 参数数量/ 106 | IoU / % | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 车 | 自行车 | 摩托车 | 卡车 | 其他 车辆 | 人 | 自行 车手 | 摩托 车手 | 路面 | 停车牌 | 人行道 | 其他 路面 | ||||
| 点 | Pointnet | 14.6 | 3.0 | 46.3 | 1.3 | 0.3 | 0.1 | 0.8 | 0.2 | 0.2 | 0.0 | 61.6 | 15.8 | 35.7 | 1.4 |
| Pointnet+ | 20.1 | 6.0 | 53.7 | 1.9 | 0.2 | 0.9 | 0.2 | 0.9 | 1.0 | 0.0 | 72.0 | 18.7 | 41.8 | 5.6 | |
| SPGraph | 20.0 | 0.3 | 68.3 | 0.9 | 4.5 | 0.9 | 0.8 | 1.0 | 6.0 | 0.0 | 49.5 | 1.7 | 24.2 | 0.3 | |
| SPLATNet | 22.8 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 70.4 | 0.8 | 41.5 | 0.0 | |
| TangentConv | 35.9 | 0.4 | 86.8 | 1.3 | 12.7 | 11.6 | 10.2 | 17.1 | 20.2 | 0.5 | 82.9 | 15.2 | 61.7 | 9.0 | |
| P2Net | 39.8 | 6.0 | 85.6 | 20.4 | 14.4 | 14.4 | 11.5 | 16.9 | 24.9 | 5.9 | 87.8 | 47.5 | 67.3 | 7.3 | |
| RandLA-Net | 53.9 | 2.1 | 94.2 | 26.0 | 25.8 | 40.1 | 38.9 | 49.2 | 48.2 | 7.2 | 90.7 | 60.3 | 73.7 | 20.4 | |
| PolarNet | 54.3 | 16.6 | 93.8 | 40.3 | 30.1 | 22.9 | 28.5 | 43.2 | 40.2 | 5.6 | 90.8 | 61.7 | 74.4 | 21.7 | |
| 体素 | Cylinder3D | 67.8 | - | 97.1 | 67.6 | 64.0 | 59.0 | 58.6 | 73.9 | 67.9 | 36.0 | 91.4 | 65.1 | 75.5 | 32.3 |
| MinkowskiNet | 63.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| SPVCNN | 63.8 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| SPVCNN-lite | 58.5 | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| 投影 | Squeezeseg | 29.5 | 1.0 | 68.8 | 16.0 | 4.1 | 3.3 | 3.6 | 12.9 | 13.1 | 0.9 | 85.4 | 26.9 | 54.3 | 4.5 |
| SqueezesegV2 | 39.6 | 1.0 | 82.7 | 21.0 | 22.6 | 14.5 | 15.9 | 20.2 | 24.3 | 2.9 | 88.5 | 42.4 | 65.5 | 18.7 | |
| SqueezesegV3 | 55.9 | - | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | |
| RangeNet21 | 47.4 | 25.0 | 85.4 | 26.2 | 26.5 | 18.6 | 15.6 | 31.8 | 33.6 | 4.0 | 91.4 | 57.0 | 74.0 | 26.4 | |
| RangeNet53 | 52.2 | 50.0 | 91.4 | 25.7 | 34.4 | 25.7 | 23.0 | 38.3 | 38.8 | 4.8 | 91.8 | 65.0 | 75.2 | 27.8 | |
| MINet + k-NN | 55.2 | 2.0 | 90.1 | 41.8 | 34.0 | 29.9 | 23.6 | 51.4 | 52.4 | 25.0 | 90.5 | 59.0 | 72.6 | 25.8 | |
| Lite-HDSeg | 63.8 | - | 92.3 | 40.0 | 55.4 | 37.7 | 39.6 | 59.2 | 71.6 | 54.3 | 93.0 | 68.2 | 78.3 | 29.3 | |
| 3D-MiniNet | 55.8 | - | 90.5 | 42.3 | 42.1 | 28.5 | 29.4 | 47.8 | 44.1 | 14.5 | 91.6 | 64.2 | 74.5 | 25.4 | |
| SalsaNext | 59.5 | 6.7 | 91.9 | 48.3 | 38.6 | 38.9 | 31.9 | 60.2 | 59.0 | 19.4 | 91.7 | 63.7 | 75.8 | 29.1 | |
| FIDNet | 58.6 | 6.3 | 93.0 | 45.7 | 42.0 | 27.9 | 32.6 | 62.6 | 58.1 | 30.5 | 90.8 | 58.3 | 74.9 | 20.1 | |
| CE-Net | 64.7 | 6.9 | 91.9 | 58.6 | 50.3 | 40.6 | 42.3 | 68.9 | 65.9 | 43.5 | 90.3 | 60.9 | 75.1 | 31.5 | |
| 本文方法 | 63.9 | 5.8 | 95.3 | 46.3 | 57.0 | 79.6 | 43.1 | 68.5 | 80.5 | 0.0 | 94.8 | 48.4 | 81.8 | 0.3 | |
| 方法 | mIoU / % | IoU / % | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 人 | 骑自行车的人 | 车 | 卡车 | 植物 | 交通标志 | 杆状物 | 垃圾桶 | 建筑 | 石头 | 围墙 | 自行车 | 地面 | ||
| Sequeezeseg | 18.9 | 14.2 | 1.0 | 13.2 | 10.4 | 28.0 | 5.1 | 5.7 | 2.3 | 43.6 | 0.2 | 15.6 | 31.0 | 75.0 |
| SequeezesegV2 | 30.0 | 48.0 | 9.4 | 48.5 | 11.3 | 50.1 | 6.7 | 6.2 | 14.0 | 60.4 | 5.2 | 22.1 | 36.1 | 71.3 |
| RangeNet53 | 30.9 | 57.3 | 4.6 | 35.0 | 14.1 | 58.3 | 3.9 | 6.9 | 24.1 | 66.1 | 6.6 | 23.4 | 28.6 | 73.5 |
| MINet | 43.2 | 62.4 | 12.1 | 63.8 | 22.3 | 68.6 | 16.7 | 30.1 | 28.9 | 75.1 | 28.6 | 32.2 | 44.9 | 76.3 |
| FIDNet | 46.4 | 72.2 | 23.1 | 72.7 | 23.0 | 68.0 | 22.2 | 28.6 | 16.3 | 73.1 | 34.0 | 40.9 | 50.3 | 79.1 |
| CE-Net | 49.9 | 74.9 | 21.8 | 77.0 | 25.3 | 72.0 | 18.0 | 30.9 | 46.9 | 75.9 | 26.1 | 47.5 | 51.7 | 80.7 |
| 本文方法 | 49.9 | 73.7 | 30.0 | 75.5 | 27.1 | 73.3 | 11.2 | 29.3 | 47.2 | 72.8 | 27.3 | 42.9 | 54.1 | 76.3 |
| 方法 | mIoU / % | IoU / % | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 人 | 骑自行车的人 | 车 | 卡车 | 植物 | 交通标志 | 杆状物 | 垃圾桶 | 建筑 | 石头 | 围墙 | 自行车 | 地面 | ||
| Sequeezeseg | 18.9 | 14.2 | 1.0 | 13.2 | 10.4 | 28.0 | 5.1 | 5.7 | 2.3 | 43.6 | 0.2 | 15.6 | 31.0 | 75.0 |
| SequeezesegV2 | 30.0 | 48.0 | 9.4 | 48.5 | 11.3 | 50.1 | 6.7 | 6.2 | 14.0 | 60.4 | 5.2 | 22.1 | 36.1 | 71.3 |
| RangeNet53 | 30.9 | 57.3 | 4.6 | 35.0 | 14.1 | 58.3 | 3.9 | 6.9 | 24.1 | 66.1 | 6.6 | 23.4 | 28.6 | 73.5 |
| MINet | 43.2 | 62.4 | 12.1 | 63.8 | 22.3 | 68.6 | 16.7 | 30.1 | 28.9 | 75.1 | 28.6 | 32.2 | 44.9 | 76.3 |
| FIDNet | 46.4 | 72.2 | 23.1 | 72.7 | 23.0 | 68.0 | 22.2 | 28.6 | 16.3 | 73.1 | 34.0 | 40.9 | 50.3 | 79.1 |
| CE-Net | 49.9 | 74.9 | 21.8 | 77.0 | 25.3 | 72.0 | 18.0 | 30.9 | 46.9 | 75.9 | 26.1 | 47.5 | 51.7 | 80.7 |
| 本文方法 | 49.9 | 73.7 | 30.0 | 75.5 | 27.1 | 73.3 | 11.2 | 29.3 | 47.2 | 72.8 | 27.3 | 42.9 | 54.1 | 76.3 |




| 类型 | 模型名称及结构 | 参数数量,M / 106 | FLOPs / 109 | mIoU / % |
|---|---|---|---|---|
| 基准 | SalsaNext (5C + BI) | 5.9 | 177.28 | 57.9 |
| CE-Net (5C + BI) | 7.2 | 480.33 | 64.3 | |
| 本文方法 | RangeFormer-Net (4C + M + BI) | 5.0 | 161.59 | 58.5 |
| RangeFormer (3C + 2×M + BI) | 5.2 | 165.84 | 59.7 | |
| RangeFormer-Net (2C + 3×M + BI) | 5.3 | 168.39 | 61.3 | |
| RangeFormer-Net (C + 4M + BI) | 5.6 | 170.75 | 62.1 | |
| RangeFormer-Net (5M + BI) | 5.6 | 171.81 | 62.4 |
| 类型 | 模型名称及结构 | 参数数量,M / 106 | FLOPs / 109 | mIoU / % |
|---|---|---|---|---|
| 基准 | SalsaNext (5C + BI) | 5.9 | 177.28 | 57.9 |
| CE-Net (5C + BI) | 7.2 | 480.33 | 64.3 | |
| 本文方法 | RangeFormer-Net (4C + M + BI) | 5.0 | 161.59 | 58.5 |
| RangeFormer (3C + 2×M + BI) | 5.2 | 165.84 | 59.7 | |
| RangeFormer-Net (2C + 3×M + BI) | 5.3 | 168.39 | 61.3 | |
| RangeFormer-Net (C + 4M + BI) | 5.6 | 170.75 | 62.1 | |
| RangeFormer-Net (5M + BI) | 5.6 | 171.81 | 62.4 |
| 类型 | 模型名称及结构 | 参数数量,M / 106 | FLOPs / 109 | mIoU / % |
|---|---|---|---|---|
| 基准 | SalsaNext (5×C + Decoders) | 6.7 | 62.30 | 59.5 |
| CE-Net (5×C + BI) | 6.8 | 434.27 | 64.7 | |
| 本文方法 | RangeFormer-Net (5×M + Decoders) | 5.8 | 58.94 | 63.1 |
| 类型 | 模型名称及结构 | 参数数量,M / 106 | FLOPs / 109 | mIoU / % |
|---|---|---|---|---|
| 基准 | SalsaNext (5×C + Decoders) | 6.7 | 62.30 | 59.5 |
| CE-Net (5×C + BI) | 6.8 | 434.27 | 64.7 | |
| 本文方法 | RangeFormer-Net (5×M + Decoders) | 5.8 | 58.94 | 63.1 |
| [1] | 曹行健, 张志涛, 孙彦赞, 等. 面向智慧交通的图像处理与边缘计算[J]. 中国图象图形学报, 2022, 27(6): 1743-1767. |
| CAO Xingjian, ZHANG Zhitao, SUN Yanzan, et al. Image Processing and Edge Computing for Intelligent Transportation[J]. J Imag Graph, 2022, 27(6): 1743-1767. (in Chinese) | |
| [2] | 胡远志, 刘俊生, 何佳, 等. 基于激光雷达点云与图像融合的车辆目标检测方法[J]. 汽车安全与节能学报, 2019, 10(4): 451-458. |
| HU Yuanzhi, LIU Junsheng, HE Jia, et al. Vehicle target detection method based on lidar point cloud and image fusion[J]. J Auto Safety Energy, 2019, 10(4): 451-458. (in Chinese) | |
| [3] | DONG Huixu, YU Haoyong, GUO Chuangqiang, et al. Real-time avoidance strategy of dynamic obstacles via half model-free detection and tracking with 2d lidar for mobile robots[J]. IEEE/ASME Transa Mech, 2020, 26(4): 2215-2225. |
| [4] | 刘畅, 赵津, 刘子豪, 等. 基于欧氏聚类的改进激光雷达障碍物检测方法[J]. 激光与光电子学进展, 2020,57(20):1-7. |
| LIU Chang, ZHAO Jin, LIU Zihao, et al. Improved LiDAR obstacle detection method based on euclidean clustering[J]. Laser Optoelectr Progr, 2020, 57(20): 1-7. (in Chinese) | |
| [5] | 李茂月, 吕虹毓, 河香梅, 等. 自动驾驶中周围车辆识别与信息地图构建技术[J]. 汽车安全与节能学报, 2022, 13(1): 131-141. |
| LI Maoyue, LÜ Hongyu, HE Xiangmei, et al. Surrounding vehicle recognition and information map construction technology in autonomous driving[J]. J Auto Safety Energy, 2022, 13(1): 131-141. (in Chinese) | |
| [6] | YANG Hui, CHEN Yaya, LIU Junxiao, et al. A 3D Lidar SLAM system based on semantic segmentation for rubber-tapping robot[J]. Forests, 2023, 14(9): 1856-1602 |
| [7] | WANG Fei, YANG Yujie, ZHOU Jingchun, et al. An onboard point cloud semantic segmentation system for robotic platforms[J]. Machines, 2023, 11(5): 571-584 |
| [8] | ZHU Xinge, ZHOU Hui, WANG Tai, et al. Cylindrical and asymmetrical 3d convolution networks for lidar segmentation[C]// Proc IEEE/CVF Conf Compu Vision Patt Recogn, 2021: 9939-9948. |
| [9] | Jhaldiyal A, Chaudhary N. Semantic segmentation of 3D LiDAR data using deep learning: a review of projection-based methods[J]. Applied Intelligence, 2023, 53(6): 6844-6855. |
| [10] | ZHANG Yang, ZHOU Zixiang, David P, et al. Polarnet: An improved grid representation for online lidar point clouds semantic segmentation[C]// Proc IEEE/CVF Conf Compu Vision Patt Recogn, 2020: 9601-9610. |
| [11] | WU Bichen, ZHOU Xuanyu, ZHAO Sicheng, et al. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud[C]// 2019 Int’l Conf Robot Autom (ICRA), IEEE, 2019: 4376-4382. |
| [12] | WU Bichen, WAN Alvin, YUE Xiangyu, et al. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud[C]// 2018 IEEE Int’l Conf’Robot’Automation (ICRA). IEEE, 2018: 1887-1893. |
| [13] | Milioto A, Vizzo I, Behley J, et al. Rangenet++: Fast and accurate lidar semantic segmentation[C]// 2019 IEEE/RSJ Int’l Conf Intell Robot Syst (IROS). IEEE, 2019: 4213-4220. |
| [14] | Aksoy E E, Baci S, Cavdar S. Salsanet: Fast road and vehicle segmentation in lidar point clouds for autonomous driving[C]// 2020 IEEE Intell Vehi Symp (IV). IEEE, 2020: 926-932. |
| [15] | Cortinhal T, Tzelepis G, Erdal Aksoy E. Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds[C]// Adva Visual Comput 15th Int’l Symp, ISVC 2020, 2020: 207-222. |
| [16] | Charles R. Qi, SU Hao, Mo Kaichun, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]// Proc IEEE Conf Compu Vision Patt Recogn, 2017: 652-660. |
| [17] | HU Qingyong, YANG Bo, XIE Linhai, et al. Randla-net: Efficient semantic segmentation of large-scale point clouds[C]// Proc IEEE Conf Compu Vision Patt Recogn, 2020: 11108-11117. |
| [18] | Thomas H, Qi C R, Deschaud J E, et al. Kpconv: Flexible and deformable convolution for point clouds[C]// Proc of the IEEE/CVF Int’l Conf Compu Vision, 2019: 6411-6420. |
| [19] | Tchapmi L, Choy C, Armeni I, et al. Segcloud: Semantic segmentation of 3d point clouds[C]// 2017 Int’l Conf 3D Vision (3DV), IEEE, 2017: 537-547. |
| [20] | TANG Haotian, LIU Zhijian, ZHAO Shengyu, et al. Searching efficient 3d architectures with sparse point-voxel convolution[C]// Eur Conf Comput Vision. Cham: Springer Int’l Publ, 2020: 685-702. |
| [21] | GUO MengHao, CAI JunXiong, LIU ZhengNing, et al. Pct: Point cloud transformer[J]. Computational Visual Media, 2021, 7(2): 187-199. |
| [22] | Park C, Jeong Y, Cho M, et al. Fast point transformer[C]// Proc IEEE/CVF Int’l Conf Compu Vision, 2022: 16949-16958. |
| [23] | Behley J, Garbade M, Milioto A, et al. Semantickitti: A dataset for semantic scene understanding of lidar sequences[C]// Proc IEEE/CVF Int’l Conf Compu Vision, 2019: 9297-9307. |
| [24] | PAN Yancheng, GAO Biao, MEI Jilin, et al. Semanticposs: A point cloud dataset with large quantity of dynamic instances[C]// 2020 IEEE Intell Vehicles Symp (IV), IEEE, 2020: 687-693. |
| [25] | Cortinhal T, Kurnaz F, Aksoy E E. Semantics-aware multi-modal domain translation: From LiDAR point clouds to panoramic color images[C]// Proc IEEE/CVF Int’l Conf Compu Vision, 2021: 3032-3048. |
| [26] | HENG Huixian, HAN Xianfeng, XIAO Guoqiang. CENet: Toward concise and efficient LiDAR semantic segmentation for autonomous driving[C]// 2020 IEEE Int’l Conf’ Multimedia Expo (ICME), IEEE, 2022: 01-06. |
| [27] | SHAN Tixiao, Englot B, Meyers D, et al. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping[C]// 2020 IEEE/RSJ Int’l Conf Intell Robot Syst, IEEE, 2020: 5135-5142. |
| [28] | CHEN Xieyuanli, Milioto A, Palazzolo E, et al. Suma++: Efficient lidar-based semantic slam[C]// 2020 IEEE/RSJ Int’l Conf Intell Robot Syst, IEEE, 2019: 4530-4537. |
| [1] | 潘玉恒, 任晨, 鲁维佳, 李洋. 基于双重池化注意力机制和竖直特征融合的DV-PointPillars三维目标检测模型[J]. 汽车安全与节能学报, 2025, 16(5): 793-801. |
| [2] | 石丽英, 周国峰, 李泽星, 曹莉凌. 基于3DSSD的差异路口自适应联邦学习算法[J]. 汽车安全与节能学报, 2024, 15(5): 732-741. |
| [3] | 李彩虹, 何晨阳, 高锋, 陈佳欣. 一种基于目标点云分布特性的动态聚类算法[J]. 汽车安全与节能学报, 2024, 15(2): 261-267. |
| [4] | 朱波, 张纪伟, 谈东奎, 胡旭东. 基于多源传感器与导航地图的端到端自动驾驶方法[J]. 汽车安全与节能学报, 2022, 13(4): 738-749. |
| [5] | 朱艳, 谢忠志, 于雯, 李曙生, 张逊. 低光照环境下基于面部特征点的疲劳驾驶检测技术[J]. 汽车安全与节能学报, 2022, 13(2): 282-289. |
| [6] | 胡远志, 蒋涛, 刘西, 施友宁. 基于双流自适应图卷积神经网络的行人过街意图识别[J]. 汽车安全与节能学报, 2022, 13(2): 325-332. |
| [7] | 申恩恩,胡玉梅,陈光,罗攀,朱浩. 智能驾驶实时目标检测的深度卷积神经网络[J]. JASE, 2020, 11(1): 111-116. |
| [8] | 胡远志,刘俊生,何佳,肖航,宋佳. 基于激光雷达点云与图像融合的车辆目标检测方法[J]. JASE, 2019, 10(4): 451-458. |
| [9] | 白 傑,郝培涵,陈思汉. 用轻量化卷积神经网络图像语义分割的交通场景理解[J]. JASE, 2018, 9(4): 433-440. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||