欢迎访问《汽车安全与节能学报》,
汽车安全与节能学报 ›› 2024, Vol. 15 ›› Issue (5): 702-710.DOI: 10.3969/j.issn.1674-8484.2024.05.008
柳鹏1( ), 赵克刚1,*(), 梁志豪1, 叶杰2
), 赵克刚1,*(), 梁志豪1, 叶杰2
收稿日期:2024-05-15
修回日期:2024-10-09
出版日期:2024-10-31
发布日期:2024-11-07
通讯作者:
赵克刚,副教授。E-mail:作者简介:柳鹏(2001—),男(汉),江西,硕士研究生。E-mail:202320100998@mail.scut.edu.cn。
基金资助:
LIU Peng1(), ZHAO Kegang1,*(), LIANG Zhihao1, YE Jie2
Received:2024-05-15
Revised:2024-10-09
Online:2024-10-31
Published:2024-11-07
摘要:
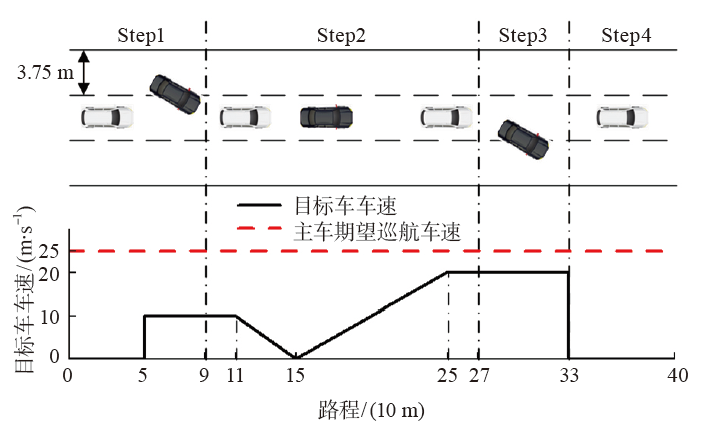
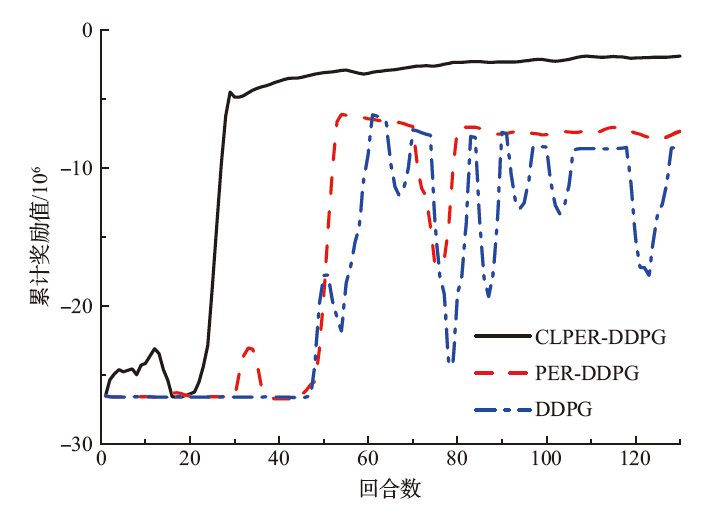
为了解决车辆纵向速度规划任务中规划器不易收敛以及在多场景之间切换时稳定性差的问题,基于多层感知机设计了车辆纵向速度规划器,构建了结合优先经验回放机制和课程学习机制的深度确定性策略梯度算法。该文设计了仿真场景进行模型的训练和测试,并对深度确定性策略梯度(DDPG)、结合优先经验回放机制的深度确定性策略梯度(PER-DDPG)、结合优先经验回放机制和课程学习机制的深度确定性策略梯度(CLPER-DDPG)3种算法进行对比实验,并在园区内的真实道路上进行实车实验。 结果表明:相比于DDPG算法,CLPER-DDPG算法使规划器的收敛速度提高了56.45%,距离差均值降低了16.61%,速度差均值降低了15.25%,冲击度均值降低了18.96%。此外,当实验场景的环境气候和传感器硬件等参数发生改变时,模型能保证在安全的情况下完成纵向速度规划任务。
中图分类号:
柳鹏, 赵克刚, 梁志豪, 叶杰. 基于深度强化学习CLPER-DDPG的车辆纵向速度规划[J]. 汽车安全与节能学报, 2024, 15(5): 702-710.
LIU Peng, ZHAO Kegang, LIANG Zhihao, YE Jie. Vehicle longitudinal speed planning based on deep reinforcement learning CLPER-DDPG[J]. Journal of Automotive Safety and Energy, 2024, 15(5): 702-710.
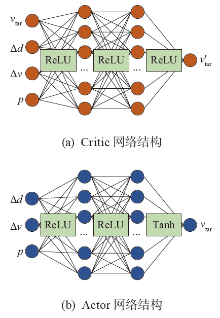
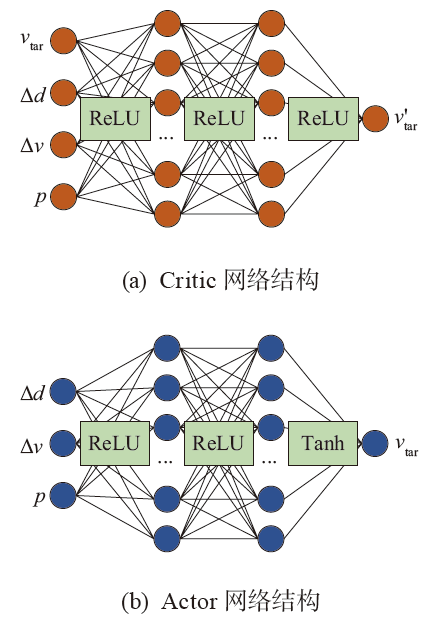
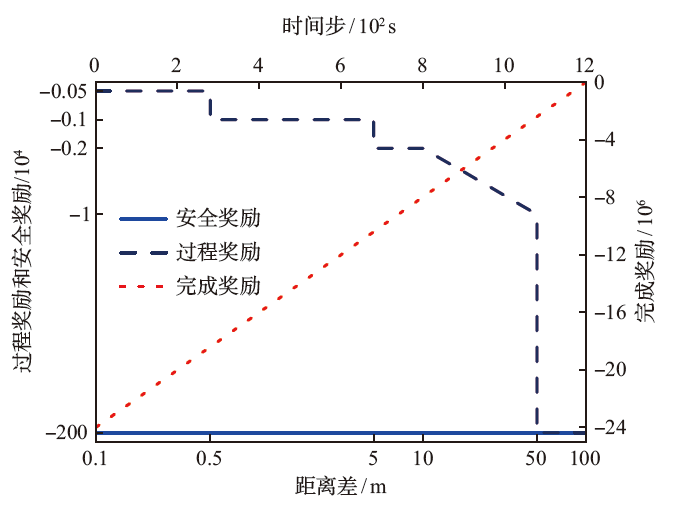
| 超参数 | 数值 |
|---|---|
| 最大回合数,K | 1 000 |
| 每回合时间步,T | 1 200 |
| 经验回放池最大容量,Dmax | 100 000 |
| 批量训练数量,batch | 64 |
| 网络学习率,lr | 0.001 |
| 折扣因子,γ | 0.995 |
| 软更新系数,η | 0.02 |
| PER超参数,[ε, α, β] | [0.01, 0.8, 0.4] |
| 权重系数,[ζ1, ζ2, ζ3, ζ4] | [8, 2, 1, 0.1] |
| 聚合因子,χ | 0.000 1 |
| 超参数 | 数值 |
|---|---|
| 最大回合数,K | 1 000 |
| 每回合时间步,T | 1 200 |
| 经验回放池最大容量,Dmax | 100 000 |
| 批量训练数量,batch | 64 |
| 网络学习率,lr | 0.001 |
| 折扣因子,γ | 0.995 |
| 软更新系数,η | 0.02 |
| PER超参数,[ε, α, β] | [0.01, 0.8, 0.4] |
| 权重系数,[ζ1, ζ2, ζ3, ζ4] | [8, 2, 1, 0.1] |
| 聚合因子,χ | 0.000 1 |
| 随机初始化: |
|---|
| Critic网络Q(s, a|θ Q)和Actor网络μ(s|θ μ); |
| Target-Critic网络Q(s, a|θ Q')和Target-Actor网络μ(s|θ μ'); |
| 经验回放池D。 |
| For (S, K) ? {(S1, K1), (S2, K2), (S3, K3), (S4, K4)} do: |
| For episode = 1, …, K do: |
| 初始化起始状态s1 |
| For t = 1, …, T do: |
| 根据策略和OU噪声输出动作at = μ(st|θ μ) + Nt |
| 获取奖励rt以及下一时刻的状态st + 1 |
| 将数据(st, at, rt, st + 1)以最大优先级存储到经验回放池D中 |
| For i = 1, …, D do: |
| 基于概率Pi采样样本 |
| 计算重要性采样权重、TD绝对误差|δi|和样本优先级pi |
| End |
| 更新Critic网络和Actor网络 |
| 更新Target-Critic和Target-Actor网络 |
| End |
| End |
| End |
| 随机初始化: |
|---|
| Critic网络Q(s, a|θ Q)和Actor网络μ(s|θ μ); |
| Target-Critic网络Q(s, a|θ Q')和Target-Actor网络μ(s|θ μ'); |
| 经验回放池D。 |
| For (S, K) ? {(S1, K1), (S2, K2), (S3, K3), (S4, K4)} do: |
| For episode = 1, …, K do: |
| 初始化起始状态s1 |
| For t = 1, …, T do: |
| 根据策略和OU噪声输出动作at = μ(st|θ μ) + Nt |
| 获取奖励rt以及下一时刻的状态st + 1 |
| 将数据(st, at, rt, st + 1)以最大优先级存储到经验回放池D中 |
| For i = 1, …, D do: |
| 基于概率Pi采样样本 |
| 计算重要性采样权重、TD绝对误差|δi|和样本优先级pi |
| End |
| 更新Critic网络和Actor网络 |
| 更新Target-Critic和Target-Actor网络 |
| End |
| End |
| End |
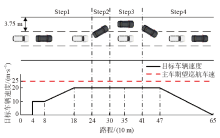
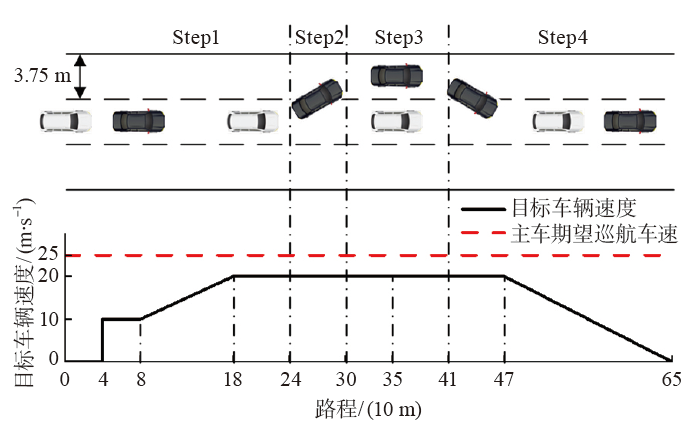
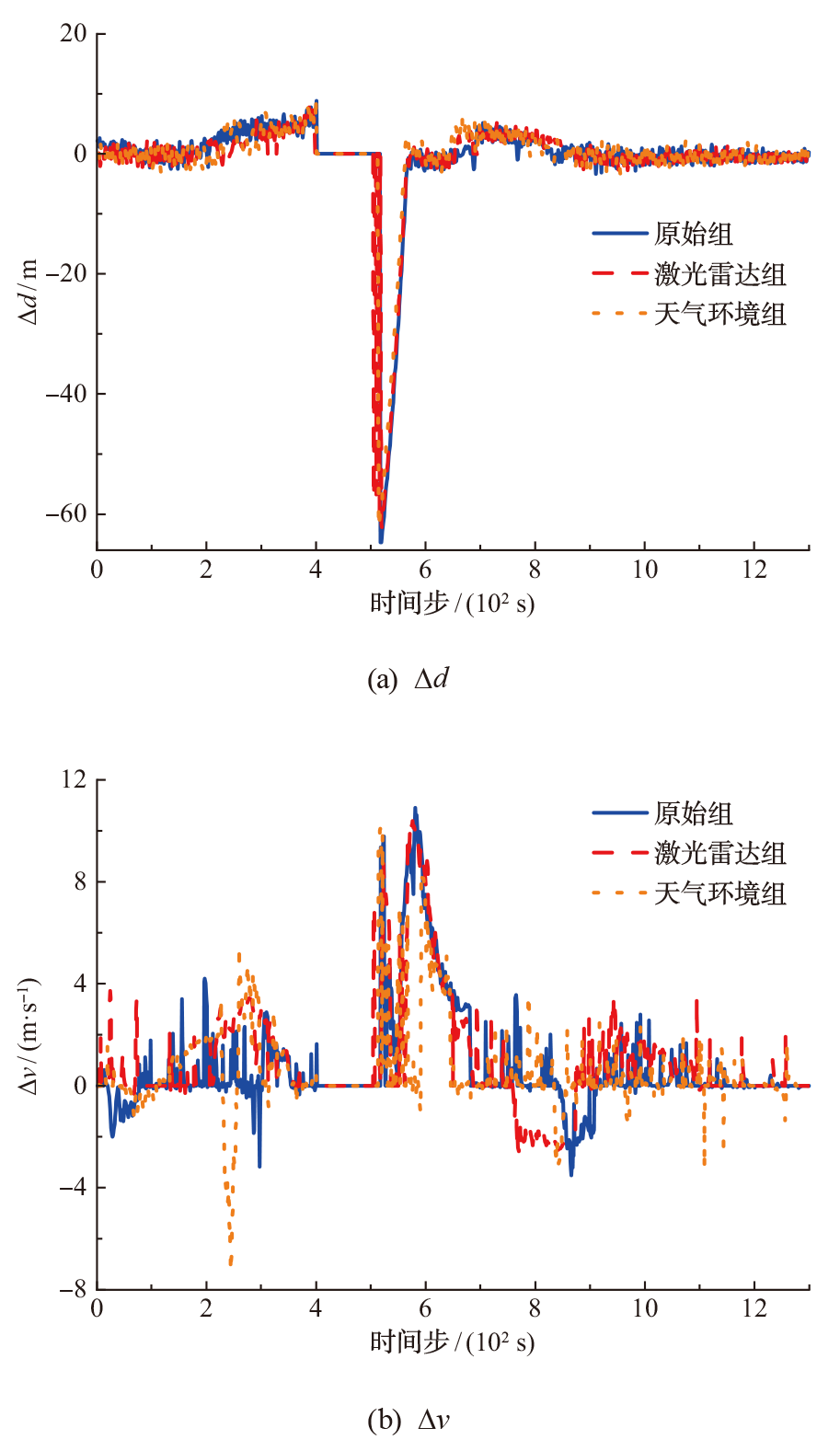


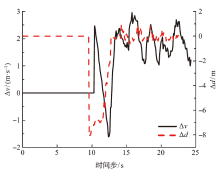
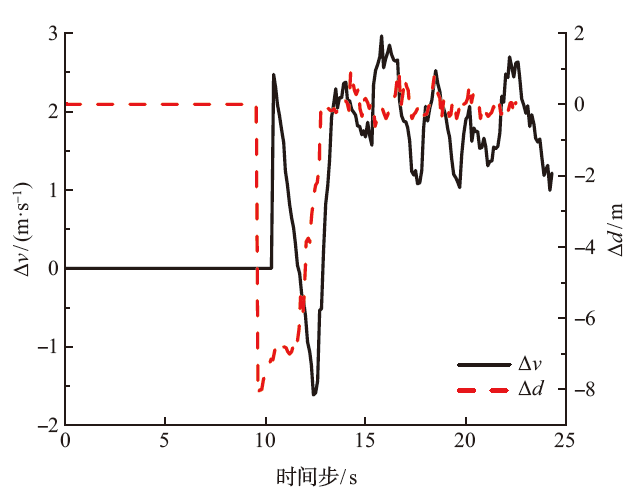
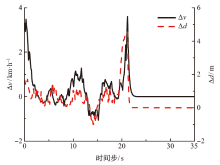
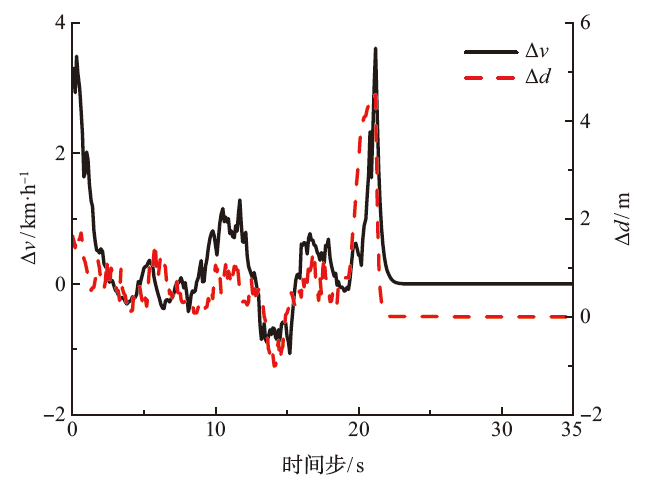
| [1] |
林泓熠, 刘洋, 李深, 等. 车路协同系统关键技术研究进展[J]. 华南理工大学学报(自然科学版), 2023, 51(10): 46-67.
doi: 10.12141/j.issn.1000-565X.230200 |
| LIN Hongyi, LIU Yang, LI Shen, et al. Research progress on key technologies in the cooperative vehicle infrastructure system[J]. J South Chin Univ Tech (Nat Sci Edit), 2023, 51(10): 46-67. (in Chinese) | |
| [2] | 芦勇, 何一超, 田贺, 等. 面向量产的自适应巡航控制系统纵向加速度规划方法研究[J]. 汽车工程, 2023, 45(10): 1803-1814. |
| LU Yong, LE Yichao, TIAN He, et al. Research on longitudinal acceleration planning method of adaptive cruise control system for mass production[J]. Autom Engineering, 2023, 45(10): 1803-1814. (in Chinese) | |
| [3] | 李旭, 谢宁, 王建春, 等. 面向切入场景的变权重自适应巡航控制策略[J]. 重庆理工大学学报(自然科学), 2023, 37(4): 10-18. |
| LI Xu, XIE Ning, WANG Jianchun. Variable weight adaptive cruise control strategy for cut-in scenes[J]. J Chongqing Univ Tech (Nat Sci), 2023, 37(4): 10-18. (in Chinese) | |
| [4] | 张德兆, 王建强, 刘佳熙, 等. 加速度连续型自适应巡航控制模式切换策略[J]. 清华大学学报(自然科学版), 2010, 50(8): 1277-1281. |
| ZHANG Dezhao, WANG Jianqiang, LIU Jiaxi, et al. Switching strategy for adaptive cruise control modes for continuous acceleration[J]. J Tsinghua Univ (Sci Tech), 2010, 50(8): 1277-1281. (in Chinese) | |
| [5] | ZHOU Yang, Ahn S, Chitturi M, et al. Rolling horizon stochastic optimal control strategy for ACC and CACC under uncertainty[J]. Transport Res Part C: Emerg Tech, 2017, 83: 61 Chinese -76. |
| [6] | CHU Hongqing, GUO Lulu, YAN Yongjun, et al. Self-learning optimal cruise control based on individual car-following style[J]. IEEE Trans Intel Transport Syst, 2020, 22(10): 6622-6633. |
| [7] |
韩天园, 沈永俊, 鲍琼, 等. 基于类人决策与横纵向协同的车辆弯道自适应巡航控制策略[J]. 中国公路学报, 2023, 36(10): 211-223.
doi: 10.19721/j.cnki.1001-7372.2023.10.017 |
| HAN Tianyuan, SHEN Yongjun, BAO Qiong, et al. Adaptive cruise control strategy for vehicle at curves based on human-like decision-making and lateral-longitudinal coordination[J]. China J Highway Transport, 2023, 36(10): 211-223. (in Chinese) | |
| [8] | 李涵, 余贵珍, 周彬, 等. 面向非结构化道路场景的车辆全局速度规划[J]. 汽车安全与节能学报, 2023, 14(3): 319-328. |
| LI Han, YU Guizhen, ZHOU Bin, et al. Vehicle global speed planning for unstructured roads scenario[J]. J Autom Safe Energ, 2023, 14(3): 319-328. (in Chinese) | |
| [9] | 何逸煦, 林泓熠, 刘洋, 等. 强化学习在自动驾驶技术中的应用与挑战[J]. 同济大学学报(自然科学版), 2024, 52(4): 520-531. |
| HE Yixu, LIN Hongyi, LIU Yang, et al. Applications and challenges of reinforcement learning in autonomous driving technology[J]. J Tongji Univ (Nat Sci), 2024, 52(4): 520-531. (in Chinese) | |
| [10] | 张新锋, 吴琳. 基于集成深度强化学习的自动驾驶车辆行为决策模型[J]. 汽车安全与节能学报, 2023, 14(4): 472-479. |
| ZHANG Xinfeng, WU Lin. Behavior decision-making model for autonomous vehicles based on an ensemble deep reinforcement learning[J]. J Autom Safe Energ, 2023, 14(4): 472-479. (in Chinese) | |
| [11] | LI Guoqiang, Görges D. Ecological adaptive cruise control for vehicles with step-gear transmission based on reinforcement learning[J]. IEEE Trans Intel Transport Syst, 2019, 21(11): 4895-4905. (in Chinese) |
| [12] |
朱冰, 蒋渊德, 赵健, 等. 基于深度强化学习的车辆跟驰控制[J]. 中国公路学报, 2019, 32(6): 53-60.
doi: 10.19721/j.cnki.1001-7372.2019.06.005 |
| ZHU Bing, JIANG Yuande, ZHAO Jian, et al. A car-following control algorithm based on deep reinforcement learning[J]. Chin J Highway Transport, 2019, 32(6): 53-60. (in Chinese) | |
| [13] | Nevmyvaka Y, FENG Yi, Kearns M. Reinforcement learning for optimized trade execution[C]// Proceed 23rd Int’l Conf Mach Learn. Pittsburgh, Pennsylvania, USA. 2006: 673-680. |
| [14] | CHENG Nuo, WANG Peng, ZHANG Guangyuan, et al. Prioritized experience replay in path planning via multi-dimensional transition priority fusion[J]. Front Neurorobot, 2023, 15(17): 171281166-1281166. |
| [15] | Golovin N, Rahm E. Reinforcement learning architecture for web recommendations[C]// Int’l Conf Info Tech: Coding Comput, 2004. Proceed. ITCC 2004. IEEE, 2004, 1: 398-402. |
| [16] | XUE Honghu, Benedikt H, Mohamed B, et al. Using deep reinforcement learning with automatic curriculum learning for mapless navigation in intralogistics[J]. Appl Sci, 2022, 12(6): 3153-3153. (in Chinese) |
| [17] |
万里鹏, 兰旭光, 张翰博, 等. 深度强化学习理论及其应用综述[J]. 模式识别与人工智能, 2019, 32(1): 67-81.
doi: 10.16451/j.cnki.issn1003-6059.201901009 |
| PENG Wanli, LAN Xuguang, ZHANG Zhang. A review of deep reinforcement learning theory and application[J]. Patt Recog Artif Intel, 2019, 32(1): 67-81. (in Chinese) | |
| [18] | Volodymyr M, Koray K, David S, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-33. |
| [19] | Lillicrap P T, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[C]// Int’l Conf Learn Represent. Google Deepmind, London, UK, 2016. |
| [1] | 文家燕, 邹海峰, 钟薇, 高博麟, 卢彦博. 融合人车博弈论的车路云一体化系统车速规划方法[J]. 汽车安全与节能学报, 2026, 17(2): 261-269. |
| [2] | 薛清元, 瞿珏, 王崴, 牛天林, 李幸. 基于信任理论的自动驾驶接管场景下HMI设计方法[J]. 汽车安全与节能学报, 2026, 17(2): 270-277. |
| [3] | 杨宗儒, 胡韫泽, 刘士琪, 关阳, 吴伟, 刘畅. 停车占位状态估计的分布式主动感知的路径规划[J]. 汽车安全与节能学报, 2026, 17(1): 140-148. |
| [4] | 马腾, 马育林, 李祎承, 潘家保, 许述财. 面向自动驾驶功能通用检测的安全行车量化评价[J]. 汽车安全与节能学报, 2026, 17(1): 59-69. |
| [5] | 吴杭哲, 焦一洲, 刘洋, 钟薇, 王水河, 郭景华, 赵健. 自动驾驶车辆紧急避撞线性时变模型预测轨迹跟踪控制[J]. 汽车安全与节能学报, 2025, 16(6): 934-944. |
| [6] | 郑讯佳, 曹泽义, 陈星, 刘辉, 高建杰. 基于自适应预测时域MPC的轨迹跟踪控制[J]. 汽车安全与节能学报, 2025, 16(5): 773-783. |
| [7] | 潘玉恒, 任晨, 鲁维佳, 李洋. 基于双重池化注意力机制和竖直特征融合的DV-PointPillars三维目标检测模型[J]. 汽车安全与节能学报, 2025, 16(5): 793-801. |
| [8] | 于谦, 郭圆圆, 杨鸣鹏, 张玉婷. 基于跟驰对的CO2排放特性的生态车辆跟驰策略[J]. 汽车安全与节能学报, 2025, 16(4): 577-586. |
| [9] | 欧阳德霖, 邱一凡, 王英臣, 阳亮, 闵海根, 王文军, 李国法. 端到端的多任务车辆自动驾驶行为决策模型[J]. 汽车安全与节能学报, 2025, 16(4): 610-619. |
| [10] | 李国法, 欧阳德霖, 陈晨, 聂冰冰, 张伟, 禹慧丽, 刘斌, 张强, 王文军, 成波, 李升波. 驾驶风险监测与干预技术研究综述[J]. 汽车安全与节能学报, 2025, 16(2): 181-196. |
| [11] | 胡志龙, 裴晓飞, 周洪龙, 魏炜冉. 基于风险敏感的自动驾驶汽车分层强化学习决策[J]. 汽车安全与节能学报, 2025, 16(2): 326-333. |
| [12] | 杨俊儒, 郑四发, 许述财, 田野, 孙剑, 孙川, 李浩然. 基于OnSite平台的自动泊车测评工具的研究与设计[J]. 汽车安全与节能学报, 2025, 16(2): 334-343. |
| [13] | 杨澜, 赵祥模, 王润民, 王振, 房山, 瞿广跃. 自动驾驶认知能力测试评价研究综述[J]. 汽车安全与节能学报, 2025, 16(1): 1-15. |
| [14] | 李怡, 刘显贵, 唐耀红, 陈立沛, 陈洋睿, 游铭娴. 变曲率道路下自动驾驶小客车安全稳定跟踪控制策略[J]. 汽车安全与节能学报, 2025, 16(1): 136-147. |
| [15] | 刘擎超, 王瑞海, 蔡英凤, 王海, 陈龙. 基于CatBoost和SHAP的高级别自动驾驶车辆非预期停车冲突风险预测[J]. 汽车安全与节能学报, 2025, 16(1): 170-180. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||