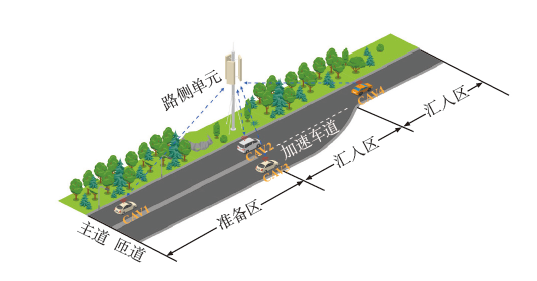
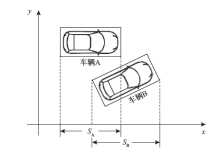
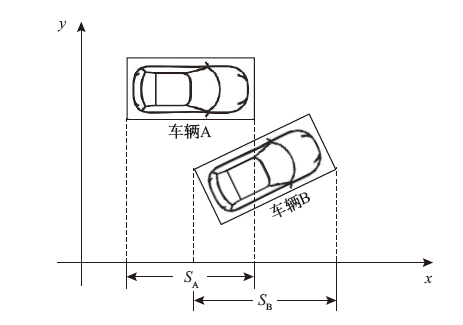
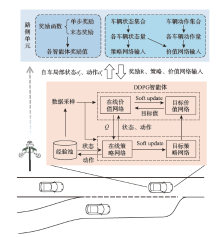
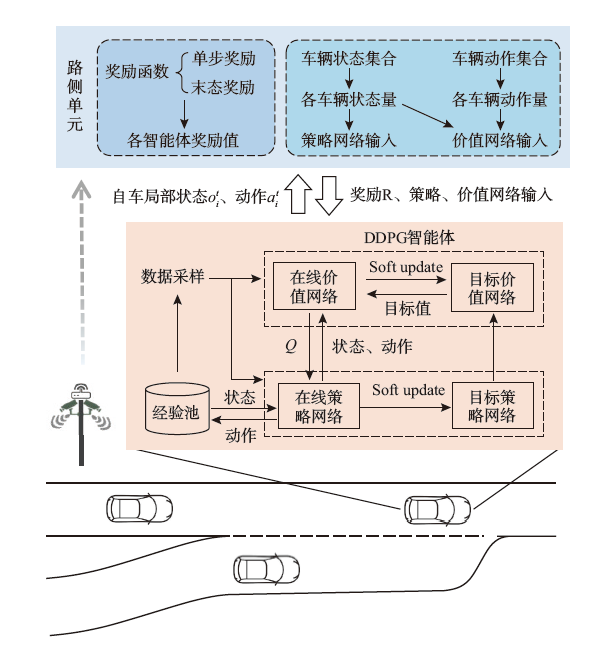
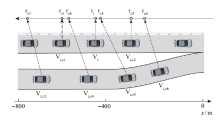
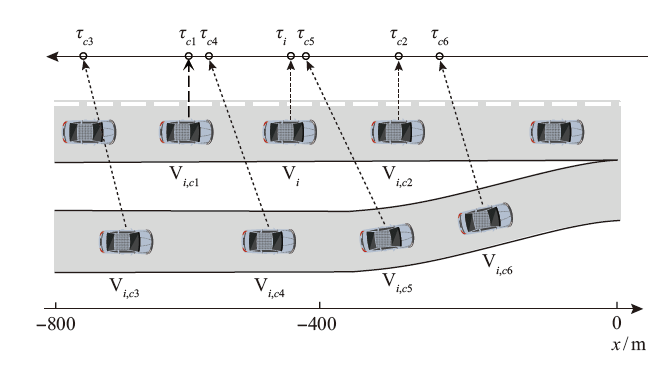
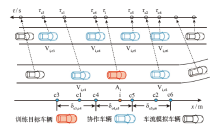
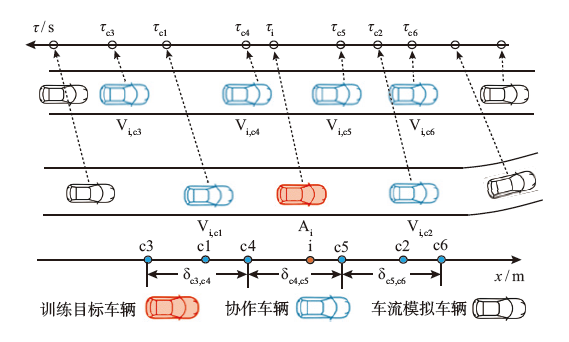
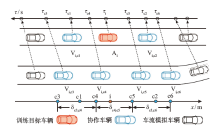
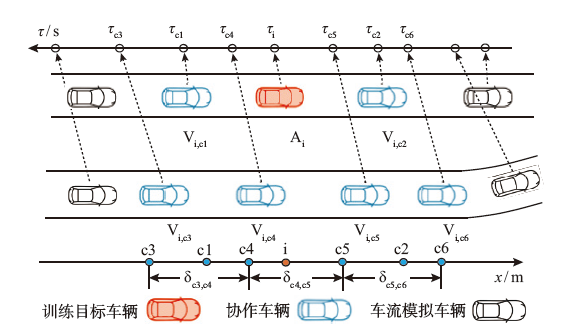
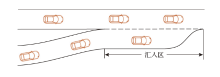
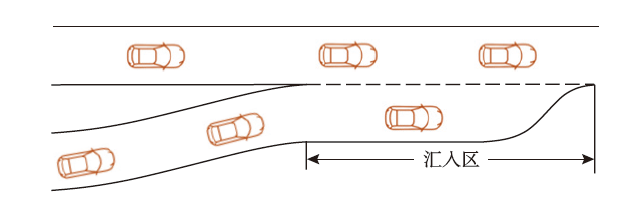
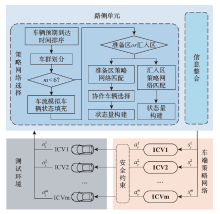
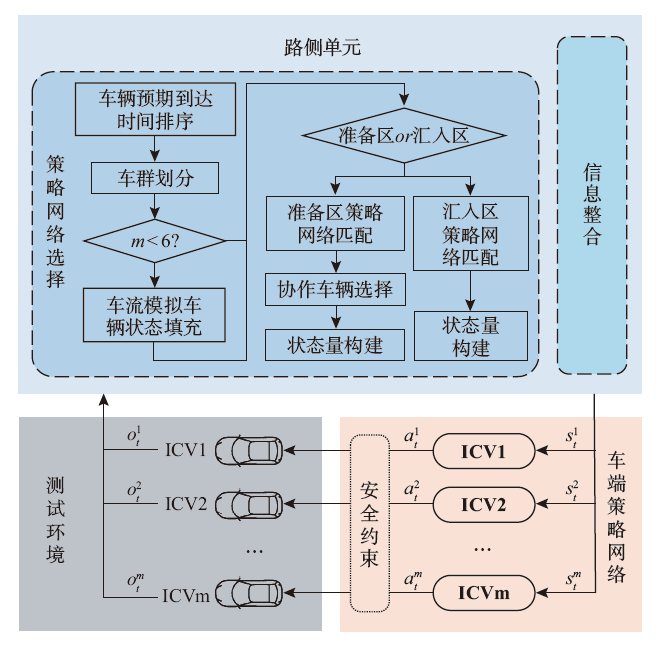
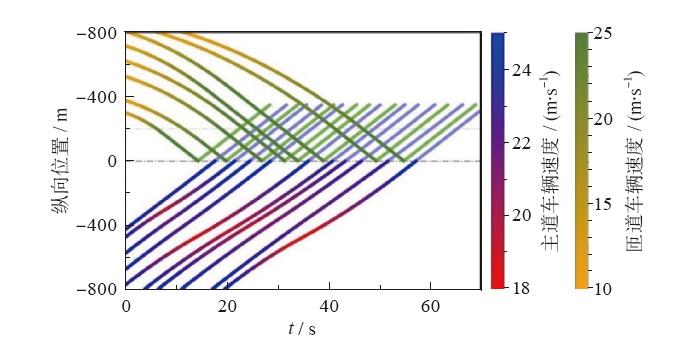
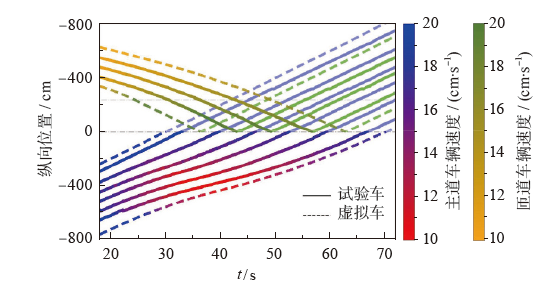
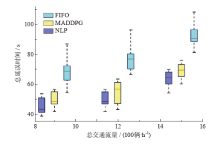
| [1] |
ZHAO Zhouqiao, WANG Ziran, WU Guoyuan, et al. The state-of-the-art of coordinated ramp control with mixed traffic conditions [C]// 2019 IEEE Intel Transport Syst Conf (ITSC). IEEE, 2019: 1741-1748.
|
| [2] |
李克强, 戴一凡, 李升波. 智能网联汽车(ICV)技术的发展现状及趋势[J]. 汽车安全与节能学报, 2017, 8(1): 1-14.
|
|
LI Keqiang, DAI Yifan, LI Shengbo, et al. State-of-the-art and technical trends of intelligent and connected vehicles[J]. J Autom Safe Energ, 2017, 8(1): 1-14. (in Chinese)
|
| [3] |
Rios-Torres J, Malikopoulos A A. A survey on the coordination of connected and automated vehicles at intersections and merging at highway on-ramps[J]. IEEE Trans Intel Transport Syst, 2016, 18(5): 1066-1077.
|
| [4] |
LI Li, WEN Ding, YAO Danya. A survey of traffic control with vehicular communications[J]. IEEE Trans Intel Transport Syst, 2013, 15(1): 425-432.
|
| [5] |
刘畅. 匝道合流区智能网联多车协调规划与控制研究[D]. 南京: 东南大学, 2021.
|
|
LIU Chang. Coordination and control of multiple connected and automated vehicles for cooperative on-ramps merging[D]. Jiangsu: Southeast University, 2021. (in Chinese)
|
| [6] |
XU Linghui, LU Jia, RAN Bin, et al. Cooperative merging strategy for connected vehicles at highway on-ramps[J]. J Transport Engi, Part A: Syst, 2019, 145(6): 04019022.
|
| [7] |
HUANG Tianyu, SUN Zhanbo. Cooperative ramp merging for mixed traffic with connected automated vehicles and human-operated vehicles[J]. IFAC-Papers On Line, 2019, 52(24): 76-81.
|
| [8] |
XUE Yongjie, DING Chuan, YU Bin, et al. A platoon-based hierarchical merging control for on-ramp Vehicles under connected environment[J]. IEEE Trans Intel Transport Syst, 2022. 23(11): 21821-21832.
|
| [9] |
关小魁, 胡茂彬. 智能网联汽车基于分组交替的协同合并策略[J]. 汽车安全与节能学报, 2022, 13(3): 482-488.
|
|
GUAN Xiaokui, HU Maobin. Grouping-alternation-based cooperative merging strategy for connected and automated vehicles[J]. J Autom Safe Energ, 2022, 13(3): 482-488. (in Chinese)
|
| [10] |
冯耀, 景首才, 惠飞. 基于深度强化学习的智能网联车辆换道轨迹规划方法[J]. 汽车安全与节能学报, 2022, 13(4): 705-717.
|
|
FENG Yao, JING Shoucai, HUI Fei, et al. Deep reinforcement learning-based lane-changing trajectory planning method of intelligent and connected vehicles[J]. J Autom Safe Energ, 2022, 13(4): 705-717. (in Chinese)
|
| [11] |
REN Tianzhu, XIE Yuanchang, JIANG Liming. Cooperative highway work zone merge control based on reinforcement learning in a connected and automated environment[J]. Transport Res Record, 2020, 2674(10): 363-374.
|
| [12] |
ZHOU Shanxing, ZHUANG Weichao, YIN Guodong, et al. Cooperative on-ramp merging control of connected and automated vehicles: Distributed multi-agent deep reinforcement learning approach [C]// 2022 IEEE 25th Int’l Conf Intel Transport Syst (ITSC). IEEE, 2022: 402-408.
|
| [13] |
ZHUANG Huanbiao, LEI Chaofan, CHEN Yuanhang, et al. Cooperative decision-making for mixed traffic at an unsignalized intersection based on multi-agent reinforcement learning[J]. Appl Sci, 2023, 13(8): 5018.
|
| [14] |
CHEN Dong, Hajidavalloo M R, LI Zhaojian, et al. Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic[J]. IEEE Trans Intel Transport Syst, 2023, 24(11): 11623-11638.
|
| [15] |
WANG Pin, CHAN Ching-Yao. Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge [C]// 2017 IEEE 20th Int’l Conf Intel Transport Syst (ITSC). IEEE, 2017: 1-6.
|
| [16] |
Yadav P, Mishra A, Kim S. A comprehensive survey on multi-agent reinforcement learning for connected and automated vehicles[J]. Sensors, 2023, 23(10): 4710.
|
| [17] |
CHEN Liang, GUO Ting, LIU Yun-ting, et al. Survey of multi-agent strategy based on reinforcement learning [C]// 2020 Chin Contr Deci Conf (CCDC). IEEE, 2020: 604-609.
|
| [18] |
Ammoun S, Nashashibi F, Laurgeau C. An analysis of the lane changing manoeuvre on roads: the contribution of inter-vehicle cooperation via communication[C]// 2007 IEEE Intel Vehi Symp. IEEE, 2007: 1095-1100.
|
| [19] |
邸允冉. 混合驾驶环境下快速路入口匝道协调控制[D]. 合肥: 合肥工业大学, 2021.
|
|
DI Yunran. Cooperative on-ramp control of freeway in mixed driving environment[D]. Hefei: Hefei Polytechnic University, 2021. (in Chinese)
|
 ), 孔伟伟1,*(
), 孔伟伟1,*(