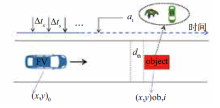
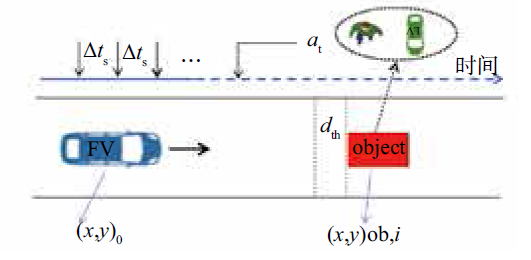
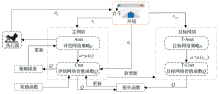
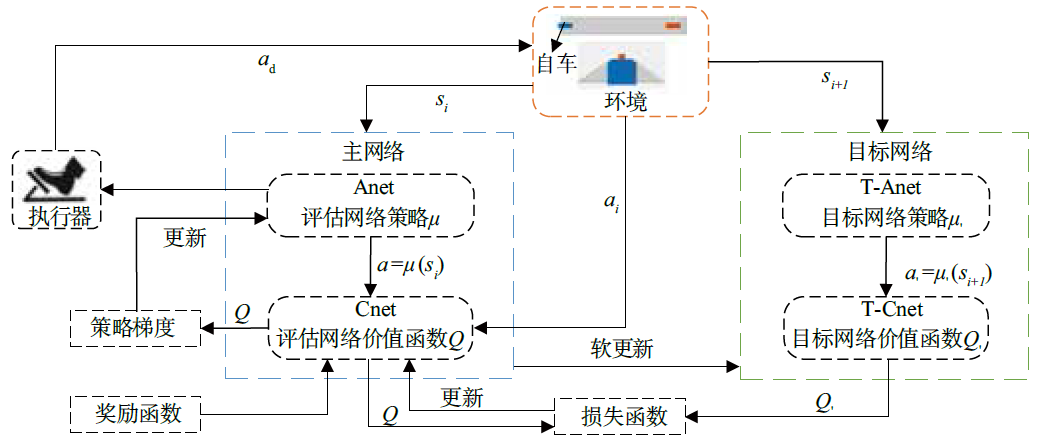
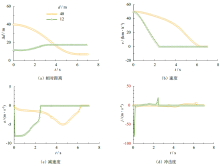
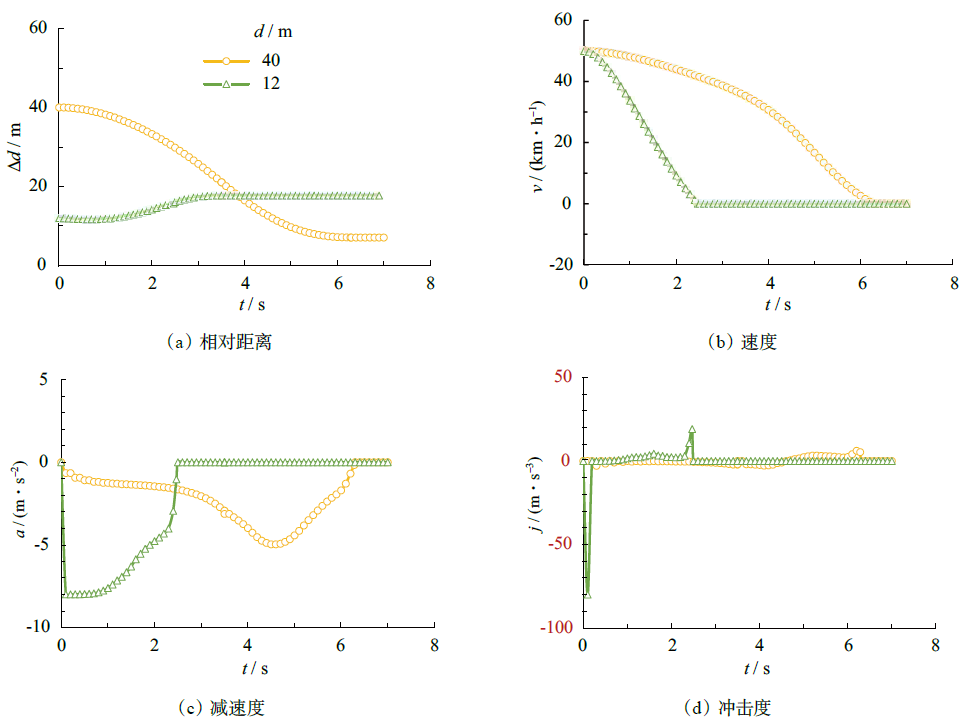
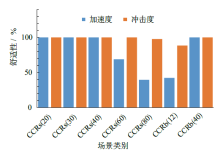
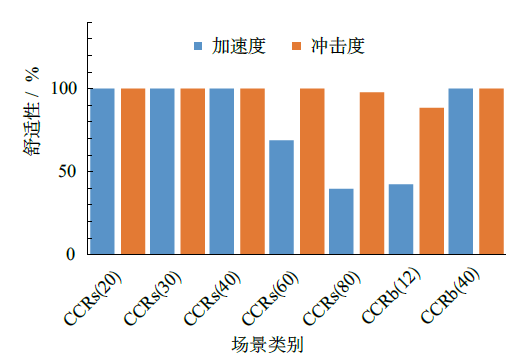
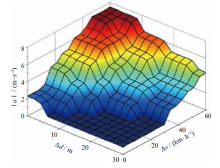
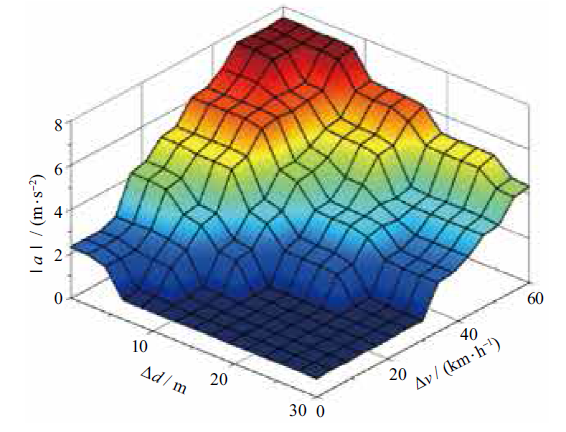
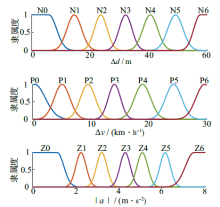
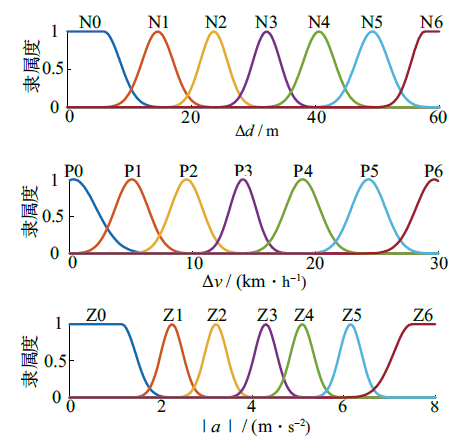
| [1] |
陈虹, 郭露露, 宫洵, 等. 智能时代的汽车控制[J]. 自动化学报, 2020,46(7):1313-1332.
|
|
CHEN Hong, GUO Lulu, GONG Xun, et al. Automotive control in intelligent era[J]. Acta Automatica Sinica, 2020,46(7):1313-1332. (in Chinese)
|
| [2] |
Kuuttis, Bowden R, JIN Yaochu, et al. A survey of deep learning applications to autonomous vehicle control[J]. IEEE Transa Intell Transp Syst, 2021,22(2):712-733.
|
| [3] |
Chae H, Kang C M, Kim B D, et al. Autonomous braking system via deep reinforcement learning[C]// 2017 IEEE 20th Int’l Conf Intel Transp Syst (ITSC). Yokohama, Japan: IEEE, 2017: 1-6.
|
| [4] |
LI Guofa, LI Shengbo, LI Shen, et al. Deep reinforcement learning enabled decision-making for autonomous driving at intersections[J]. Automotive Innovation, 2020(3):374-385.
|
| [5] |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J]. Computer Sci, 2015,8(6):187.
|
| [6] |
XIONG Xi, WANG Jianqiang, ZHANG Fang, et al. Combining deep reinforcement learning and safety-based control for autonomous driving[Z/OL]. (2020-11-10) , https://arxiv.org/abs/1612.00147v1. arXiv preprint arXiv: 1612.00147, 2016.
|
| [7] |
徐国艳, 宗孝鹏, 余贵珍, 等. 基于DDPG的无人车智能避障方法研究[J]. 汽车工程, 2019,41(2):206-212.
|
|
XU Guoyan, ZONG Xiaopeng, YU Guizhen, et al. A research on intelligent obstacle avoidance of unmanned vehicle based on DDPG algorithm[J]. Automotive Engineering, 2019,41(2):206-212. (in Chinese)
|
| [8] |
Vasquez R, Farooq B. Multi-objective autonomous braking system using naturalistic dataset[C]// 2019 IEEE Intel Transp Syst Conf (ITSC). Auckland, New Zealand: IEEE, 2019: 4348-4353.
|
| [9] |
Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[Z/OL]. (2020-11-10), https://arxiv.org/abs/1707.06347.arXiv preprint arXiv:1707.06347v2 , 2017.
|
| [10] |
李国法, 陈耀昱, 吕辰, 等. 智能汽车决策中的驾驶行为语义解析关键技术[J]. 汽车安全与节能学报, 2019,10(4):391-412.
|
|
LI Guofa, CHEN Yaoyu, LV Chen, et al. Key technique of semantic analysis of driving behavior in decision making of autonomous vehicles[J]. J Autom Safe Energ, 2019,10(2):391-412. (in Chinese)
|
| [11] |
李升波, 关阳, 侯廉, 等. 深度神经网络的关键技术及其在自动驾驶领域的应用[J]. 汽车安全与节能学报, 2019,10(2):119-145.
|
|
LI Shengbo, GUAN Yang, HOU Lian, et al. Key technique of deep neural network and its applications in autonomous driving[J]. J Autom Safe Energ, 2019,10(2):119-145. (in Chinese)
|
| [12] |
ZHU Meixin, WANG Yinhai, PU Ziyuan, et al. Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving[J]. Transp Res Part C: Emerging Tech,, 2020,117,102662.
|
| [13] |
朱冰, 蒋渊德, 赵健, 等. 基于深度强化学习的车辆跟驰控制[J]. 中国公路学报, 2019,32(6):54-60.
|
|
ZHU Bing, JIANG Yuande, ZHAO Jiao, et al. A car-following control algorithm based on deep reinforcement learning[J]. Chin J Highway Transp, 2019,32(6):54-60. (in Chinese)
|
| [14] |
朱敏, 陈慧岩. 考虑车间反应时距的汽车自适应巡航控制策略[J]. 机械工程学报, 2017,53(24):144-150.
|
|
ZHU Mi, CHEN Huiyan. Strategy for vehicle adaptive cruise control considering the reaction headway[J]. J Mech Engi, 2017,53(24):144-150. (in Chinese)
|
| [15] |
Bae I, Moon J, Seo J. Toward a comfortable driving experience for a self-driving shuttle bus[J]. Electronics, 2019,8(9):943.
doi: 10.3390/electronics8090943
URL
|
| [16] |
张春雷. 基于驾驶员避撞行为的追尾避撞控制策略研究[D]. 镇江: 江苏大学, 2017.
|
|
ZHANG Chunlei. The rear-end collision avoidance control strategy study based on drivers' avoidance behavior[D]. Zhenjiang: Jiangsu University, 2017. (in Chinese)
|
| [17] |
郑刚, 俎兆飞, 孔祚. 基于驾驶员反应时间的自动紧急制动避撞策略[J]. 重庆理工大学学报: 自然科学版, 2020,34(12):45-52.
|
|
ZHENG Gang, ZU Zhaofei, KONG Zuo. The collision avoidance strategy of automatic emergency braking system considering the response time of the driver[J]. J Chongqing Univ of Tech: Nat Sci, 2020,34(12):45-52. (in Chinese)
|
 ), 张友松(
), 张友松(